Last Updated on May 29, 2025
The demand for data engineers is growing rapidly in today’s data-driven world – and so is the competition. So even if you’re aiming to join a startup or a large tech company, it’s important to go into a data engineering interview with more than just theoretical knowledge.
Companies are looking for people who not only understand the tools and technologies – like big data frameworks and cloud platforms (at least one of AWS, Azure, or GCP) – but who can also apply that knowledge to solve real-world problems. That’s why strong preparation in both technical concepts and practical skills is key.
In this guide, I’ve put together some of the most commonly asked data engineering interview questions along with useful tips and resources to help you prepare with confidence.
Technical Categories
A good data engineer should be able to handle a variety of technical areas. During interviews, questions usually cover these key categories:
- SQL – Window functions, Advanced querying, Recursive CTE’s, Performance Tuning.
- Data Modeling – Star/snowflake schemas, normalization, slowly changing dimensions
- Cloud Tools / Pipelines – Azure Data Factory(AWS Glue/ Google Dataflow), Databricks
- Coding – Python for ETL logic, Pyspark, CI/CD.
- Data Governance – Master Data management (this is for experienced candidates – aiming for senior data engineer roles)
Top Questions and Answers
Write a SQL query to find the second highest salary in an employee table. (Beginner)
This question is a commonly asked question specially for an entry level data engineering role. This checks your basic understanding of sub-queries, window functions and applying aggregations. While there are multiple ways to solve this question, you should always consider using window functions.
You can also use OFFSET, LIMIT and other approaches. A simple approach will be using sub-queries as shown below.

However, the interviewer can tweak the question to nth largest salary, so using window functions is extremely useful in this case.

Write a SQL query to identify duplicate records in a table based on multiple columns. (Beginner)
- Expected Concepts: GROUP BY, HAVING, WINDOW functions
Another question the interviewer can ask is to remove duplicates from a table based on a few columns instead of having the entire same record duplicate. This involves identifying and then removing duplicates.
Given a table of employee salaries over time, write a query to compute the cumulative salary for each employee ordered by date (i.e., a running total of salary per employee). (Intermediate)

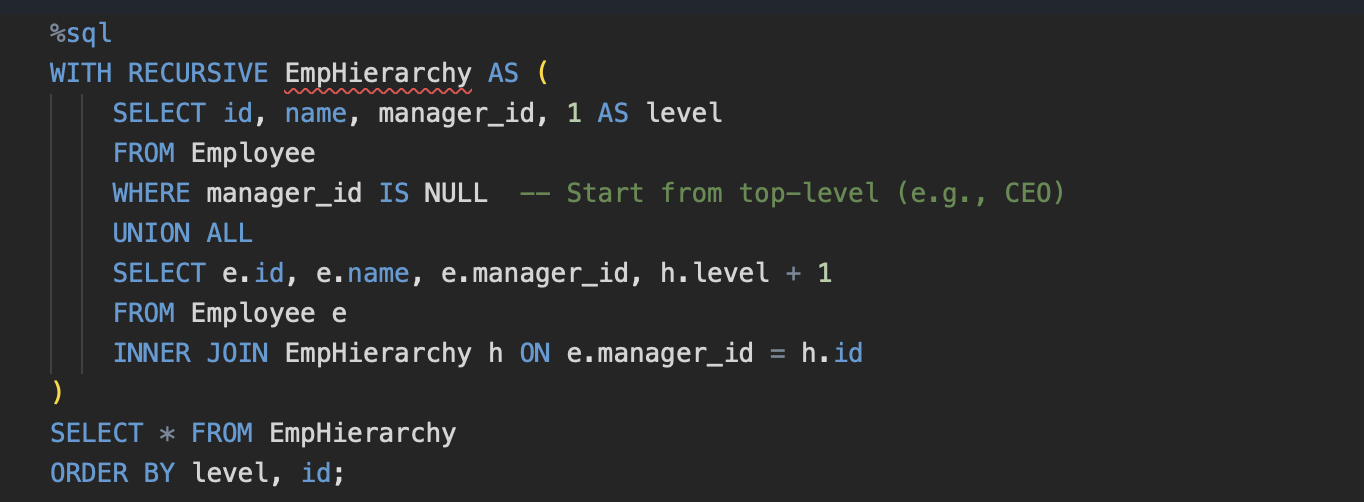
Write a Recursive Query to Find a Hierarchical Employee-Manager Structure (Advanced)
- Expected Concepts: Understanding of Recursive CTE’s
- Base case will pick employees with no manager. Recursive part joins the hierarchy recursively to find all subordinates. Level shows depth of each employee in a tree.
How to Optimize a Query with Multiple Joins and Subqueries ( Optimization )
Optimization Techniques which technical panelist will expect from your answer:
- Use EXPLAIN Plan: Analyze the query execution path.
- Avoid SELECT *: Only fetch needed columns.
- Use Indexes: Especially on join keys and WHERE filters.
- Materialize Reusable Subqueries: Use Common Table Expressions (CTEs) or temp tables.
- Check Join Order: Put the smallest/more selective tables first in nested loop joins.
- Denormalize Carefully: For read-heavy queries, reducing joins might help.
- Use Proper Join Types: Use INNER JOIN when applicable instead of LEFT JOIN.
Given a table of employee salaries over time, write a SQL query to calculate the difference in salary compared to the previous and next month for each employee. (Intermediate – Advanced)
- Expected Concepts: Understanding of LAG() and LEAD(), PARTITION BY, ORDER BY
- Calculating difference between rows and dealing with NULL values.

Data Modeling
What is a star schema and snowflake schema?
Star Schema is a central fact table linked to multiple dimension tables. Dimensions are denormalized. Whereas in snowflake schema, dimensions are normalized into multiple related tables, resembling a snowflake shape.
Follow-up:
- What are Facts and dimensions in a data warehouse?
- What is a surrogate key? Why use surrogate keys instead of natural keys?
- Difference between alternate keys, candidate keys, surrogate keys and primary keys?
- What is data normalization and denormalization? When to use each?
What is a Slowly Changing Dimension (SCD)? Why do we use it?
SCD is a technique used in data warehousing to manage and track changes in dimension data over time. Dimensions are attributes used to describe business entities (like customers or products). Because these attributes can change, SCD methods help preserve historical data or update it as per business needs.
Follow-up:
- When would you choose SCD Type 1 over Type 2?
- How do you implement SCD Type 1 and Type 2 in ETL pipelines?
- Have you used SCD in your existing project / architecture?
Modern Data Platform: Pyspark & Databricks
Describe the architecture of Apache Spark?
Follow-up:
- Explain the difference between DataFrames, Datasets and RDD.
- What is the difference between SparkSession and SparkContext? Describe the significance of lazy evaluation in Spark.
- Bucketing vs. partitioning : Partitioning splits data by columns into directories. Bucketing divides data into fixed-size buckets for better join performance.
- Explain the concept of checkpointing in Spark and why it is important.
- What is the difference between groupByKeyand reduceByKey in Spark?
How many records will spark look into the file to understand the records before concluding inferschema.
Follow-Up: How do we adjust sampling ratio for the records within the file?
What is Unity Catalog and how does it differ from the Hive Metastore in Databricks?
Follow-up:
- How does Unity Catalog manage access control at the table, schema, and catalog levels?
- Can you explain how data lineage works in Unity Catalog?
- How do you run a Databricks notebook from a workflow and pass parameters to it?
- How will you run one notebook inside another notebook? [Hint: dbutils.notebook.run() method]
Have you used transformation and functions in Pyspark?
Follow-up:
- How do you remove duplicate rows from a PySpark DataFrame? Next Question: Explain the difference between .distinct() and .dropDuplicates()
- How do you explode a nested JSON array in PySpark? Provide an example.
- How can you add a new column with the current timestamp (or with the default value)?
- How do you rename multiple columns dynamically in a DataFrame?
- How do you handle nulls during transformations like joins or withColumn() additions?
- What is the use of when() and otherwise() in PySpark? Provide a simple case statement.
How would you load incremental data in databricks delta tables?
Incremental loading means processing and loading only the new or changed data since the last update, which improves efficiency and reduces processing time. Two common approaches:
- Using Timestamps or Watermarks: Identify new or changed records in your source by comparing a timestamp column (like last_updated or modified_date) with the last load time. Query only those records where the timestamp is greater than the last processed timestamp.
- Delta Lake MERGE Operation: Databricks Delta Lake supports MERGE (upsert) which makes incremental loads simple and efficient. You can merge the incoming batch with your target Delta table to update changed rows, insert new rows, and keep unchanged rows intact.
Explain the difference between Spark Repartition and Coalesce?
- Follow up: Why to use coalesce if repartition can also decrease partitions?
Repartition() increases or decreases partitions, causing a shuffle where Coalesce() reduces partitions without a shuffle, suitable for optimization when decreasing partition count. Use repartition for better data distribution and coalesce for reducing overhead.
Explain various Spark Optimization Techniques?
- Predicate Pushdown: Filters are pushed to the data source level to reduce data read (especially effective with Parquet/ORC).
- Partition Pruning: Queries read only relevant partitions instead of the full dataset, improving scan performance.
- Broadcast Join: Small tables are broadcast to all nodes to avoid shuffles in joins (useful for small dimension tables).
- Caching and Persistence: Frequently reused datasets can be cached/persisted in memory to avoid recomputation.
- Coalesce and Repartition: increases/decreases partitions.
- Avoid Wide Transformations: Use narrow transformations (e.g., map, filter) wherever possible to reduce shuffle overhead.
- Use Delta Lake for ACID & Z-Ordering: Delta provides schema enforcement, ACID transactions, and Z-Ordering for faster filtering on large datasets.
- Skew Join Handling: Use techniques like salting to handle data skew in joins.
- Enable Adaptive Query Execution (AQE): Spark 3.x feature that optimizes joins, skew handling, and partition sizing at runtime.
Note: Each of the above highlighted terms are important and can be independently asked. Example: wide vs narrow transformations? Cache vs persist?
How would you approach debugging and resolving an OutOfMemory (OOM) error in a production Spark job?
If a Spark job fails with an OOM error in production, I first check the logs to identify where the failure occurred. Then I analyze data skew or large partitions, optimize transformations, and tune Spark configurations like executor memory and shuffle partitions. I also consider using broadcast joins, repartitioning, or caching strategies based on the job’s nature. (please elaborate each step!)
Say I am running a job with a notebook to update one of the delta table, and your colleague is running a delete command on the same delta tables, what will happen to the job – will it succeed or fail and why?
What are some key features of Delta Lake in Databricks?
Follow-up:
- What are deletion vectors in Delta Lake, and how do they help with performance?
- How do you handle the small file problem in Delta Lake?
- Can you explain how time travel works in Delta tables?
- What’s the difference between managed and external Delta tables?
- Have you used the VACUUM command? What happens if you vacuum a table too early?
- How would you restore a Delta table to an earlier version?
Cloud Services: Azure Data Factory
Can you walk me through the commonly used activities in Azure Data Factory and when you’d use them?
Follow-up:
- How does the ForEach activity handle large datasets?
- Have you used Lookup activity to dynamically drive a pipeline? How?
- What are the differences between Copy Activity and Data Flow Activity?
Suppose you need to copy data from an on-premises SQL Server to Azure Data Lake, transform the data, and load it into a Synapse table. How would you design the pipeline?
Follow-up:
- How do you parameterize the pipeline to make it reusable for different tables?
- What would you do if the source system is down during execution?
You have a requirement to process multiple files from a blob container and perform different transformations based on the file type. How would you handle this in ADF?
Follow-up:
- How would you identify file types dynamically in the pipeline?
- Can you use a single Data Flow for all file types, or would you design separate ones?
How do you implement error handling in Azure Data Factory pipelines?
Follow-up:
- What is the role of retry policies in activity configuration?
- Have you used the Until activity as part of a retry mechanism?
- How do you log failures or alerts to a monitoring system like Azure Monitor or Application Insights?
How do you manage CI/CD and version control in Azure Data Factory?
Follow-up:
- What branching strategy do you follow for ADF development and deployment?
- How do you set up automated deployment from Dev to UAT or Prod using Azure DevOps?
- Can you explain the steps involved in creating and approving a pull request for ADF pipelines?
- How do you link ADF to a Git repository, and what are the benefits?
Data Governance & Security
How do you implement data security and governance in your data pipelines?
Follow-up: Which tools or frameworks have you used to enforce data access controls and auditing?
Can you explain the difference between authentication and authorization in the context of data platforms?
Follow-up: How have you managed role-based access control (RBAC) in cloud data environments like Azure or AWS?
Scenario: Suppose sensitive data is accidentally exposed in a dataset that’s accessible to multiple teams. How would you handle the situation and prevent it in the future?
How do you ensure compliance with data privacy regulations in your ETL/ELT workflows?
Follow-up: What steps do you take to anonymize or mask sensitive data?
Describe a time when you identified and resolved a data quality or governance issue in a production system. What approach did you take, and what was the outcome?
Describe about a time you handled a data pipeline failure during a critical operation.
Describe a challenging project where you optimized a complex ETL process.
Interview Tips By Experience & Resources
Data Engineering interviews across platforms like SQL, Spark, Databricks, Snowflake, dbt, and Cloud services (Azure, GCP, AWS) become much more manageable when you focus on core concepts rather than memorizing individual questions. Just like SQL interviews revolve around patterns like aggregation functions and window functions, platform-specific interviews often test how well you understand and apply foundational tools and workflows.
For instance, in Databricks, once you’re comfortable with Delta Lake, notebook workflows, and MERGE operations, you’ll notice that many scenario-based questions follow similar themes—incremental loading, schema evolution, or access control with Unity Catalog. In Snowflake, key topics like time travel, streams & tasks, and RBAC frequently come up in different ways. Similarly, you can also check questions on dbt tools.
Across cloud platforms – whether it’s Azure, AWS or GCP, the focus is on how well you understand data orchestration, resource configuration, security (IAM), and cost optimization. When you understand these common patterns and practice with real-world examples, it becomes much easier to handle different types of interview questions confidently.
Also, earning Databricks & Cloud certifications proves you have practical, industry-relevant skills on major big data platforms – Udacity Cloud / Data Nanodegrees, Databricks Associate Data Engineer and Fabric DP700. This increases your credibility, and prepare you to handle real-world data engineering challenges efficiently.
Here are some high-quality resources to help you prepare for Data Engineering interviews, including mock interview platforms and problem sets that you can refer:
- Data Lemur : https://datalemur.com
Realistic SQL interview problems, often involving data warehouse concepts. - LeetCode SQL Problems – Focus on complex joins, window functions, CTEs, group by, case when.
Also, Udacity offers a well-structured and industry-aligned learning platform, and its Nanodegree programs are highly recommended for building both foundational and advanced expertise in the technologies discussed above. These courses feature hands-on projects, mentorship, and real-world scenarios, making them valuable resources for professionals looking to advance their careers in data engineering and analytics.
- Data Engineering with AWS: Focuses on data modeling, cloud data warehouses, data lakes, and pipeline orchestration. Ideal for learners aiming to design scalable data infrastructure on AWS.
- Data Engineering with Microsoft Azure: Focuses on implementing data solutions using Azure services like Azure Data Factory, Synapse, and Databricks.
- SQL Nanodegree: Offers a deep dive into SQL for data analysis, including advanced querying, relational databases, and performance optimization. Suitable for beginners and those refining their SQL skills.
Depending on your current level, dedicated preparation can take anywhere from 8 to 14 weeks, especially if you’re balancing a full time job. Stay consistent. Even 1–2 hours a day of focused effort adds up. Over time, you’ll not only gain the technical knowledge but also the confidence to handle any question thrown at you. Keep pushing – you’re closer than you think!