Hyperparameter tuning is a critical step in building effective machine learning models. It involves finding the optimal values for hyperparameters that control the learning process. By carefully tuning these parameters, we can significantly improve model performance and generalization. In this blog post, we’ll dive deep into the intricacies of hyperparameter tuning, explained simply.
Table of Contents
Different Techniques for Hyperparameter Tuning
Deciding Hyperparameters and Their Values
Imagine you’re baking a cake. The recipe (the model) is fixed, but you can adjust certain parameters like the oven temperature (learning rate), baking time (epochs), and the amount of sugar (regularization strength). These adjustments, or hyperparameters, significantly impact the final outcome (the model’s performance).
Just as a cake can be too dry or too moist, a model can underfit or overfit. By carefully tuning these hyperparameters, we can find the optimal recipe to produce the best possible cake, or in our case, the best-performing model.
Types of hyperparameters
Hyperparameters are configurations that influence the learning process of a machine learning model. They are not learned from the data itself but are set before training begins. Here are some common types of hyperparameters:
Random Forest

- Number of Trees (n_estimators)
Think of each tree as an expert in a specific field. A larger forest (more trees) means more experts, leading to more accurate and robust predictions. However, increasing the number of trees also increases the training time and memory usage. Therefore, it’s essential to strike a balance between accuracy and computational efficiency when selecting the optimal number of trees.
- Maximum Depth of Trees (max_depth)
Imagine each branch of the tree has a hierarchy of questions. A deeper tree can ask more specific questions and capture complex patterns. But it also increases the risk of overfitting. Limiting the depth can help prevent overfitting and improve the model’s generalization performance.
- Minimum Samples Split (min_samples_split)
This is like deciding how many leaves a branch needs to bear before it can split into further branches. A higher minimum sample split means the tree will be less complex, reducing the risk of overfitting. However, it might also miss some finer details in the data.
- Minimum Samples Leaf (min_samples_leaf)
This is like deciding how many leaves a branch must have before it can be considered a final branch (leaf node). A higher minimum sample leaf can lead to simpler trees, which can be less prone to overfitting. However, it might also reduce the model’s ability to capture complex patterns.
Neural Networks

- Learning Rate
Think of the learning rate as the student’s pace of learning. If the student (network) learns slowly and carefully, making small adjustments with each step leads to more accurate learning, but it takes longer. If students learn quickly, they might make larger mistakes and overshoot the target.
- Number of epochs
The number of epochs is like the number of times the student reviews the textbook. The student reviews the material more often, potentially leading to a deeper understanding. However, too many repetitions can lead to overfitting.
- Batch Size
The batch size is like the number of students studying together in a group. A larger group can discuss and learn from each other more effectively, but it might take longer to reach a consensus.
- Optimizer
The optimizer is like a teacher who guides the student’s learning process. Different optimizers (e.g., SGD, Adam, RMSprop) are like different teaching methods. Some teachers might focus on gradual improvement (SGD), while others might use more advanced techniques (Adam, RMSprop) to accelerate learning.
Different Techniques for Hyperparameter Tuning
Machine learning models rely on hyperparameters to function effectively. Determining the best set of hyperparameters is a complex task, often approached using three primary techniques:
- Grid Search
- Random Search
- Bayesian Optimization
Grid Search:

- How it works:
- Creates a grid of hyperparameter values.
- Trains the model for each combination of values.
- Selects the best performing combination.
- Pros: Simple to implement.
- Cons: Can be computationally expensive, especially for large grids.
Random Search:

- How it works:
- Samples random combinations of hyperparameter values.
- Can be more efficient than grid search, especially for high-dimensional spaces.
- Pros: Often finds good solutions faster than grid search.
- Cons: Less systematic than grid search. May not receive the ideal hyperparameter configuration.
Bayesian Optimization:

- How it works:
- Uses a probabilistic model to intelligently select the next hyperparameter configuration.
- Leverages past evaluations to guide the search.
- Pros: Efficient and effective, especially for expensive function evaluations.
- Cons: Can be computationally expensive for complex models.
Functional Comparison
Let’s delve into a practical example to illustrate the differences between Grid Search, Random Search, and Bayesian Optimization. We’ll use a Random Forest Classifier and the Iris dataset. We have kept the parameter grid same for all the three models to ensure the same setup and comparability of results.
Grid Search:
Random Search:
Bayesian Optimization:
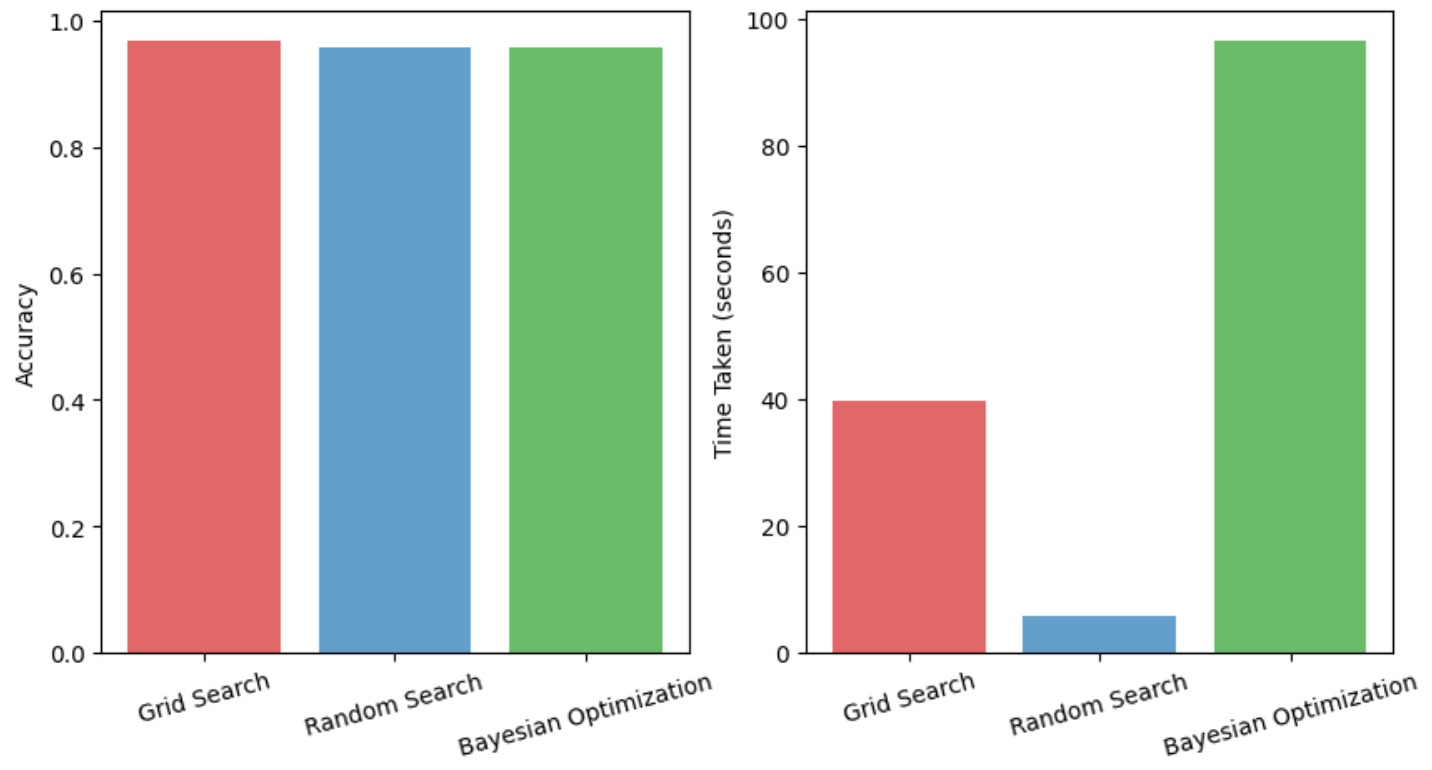
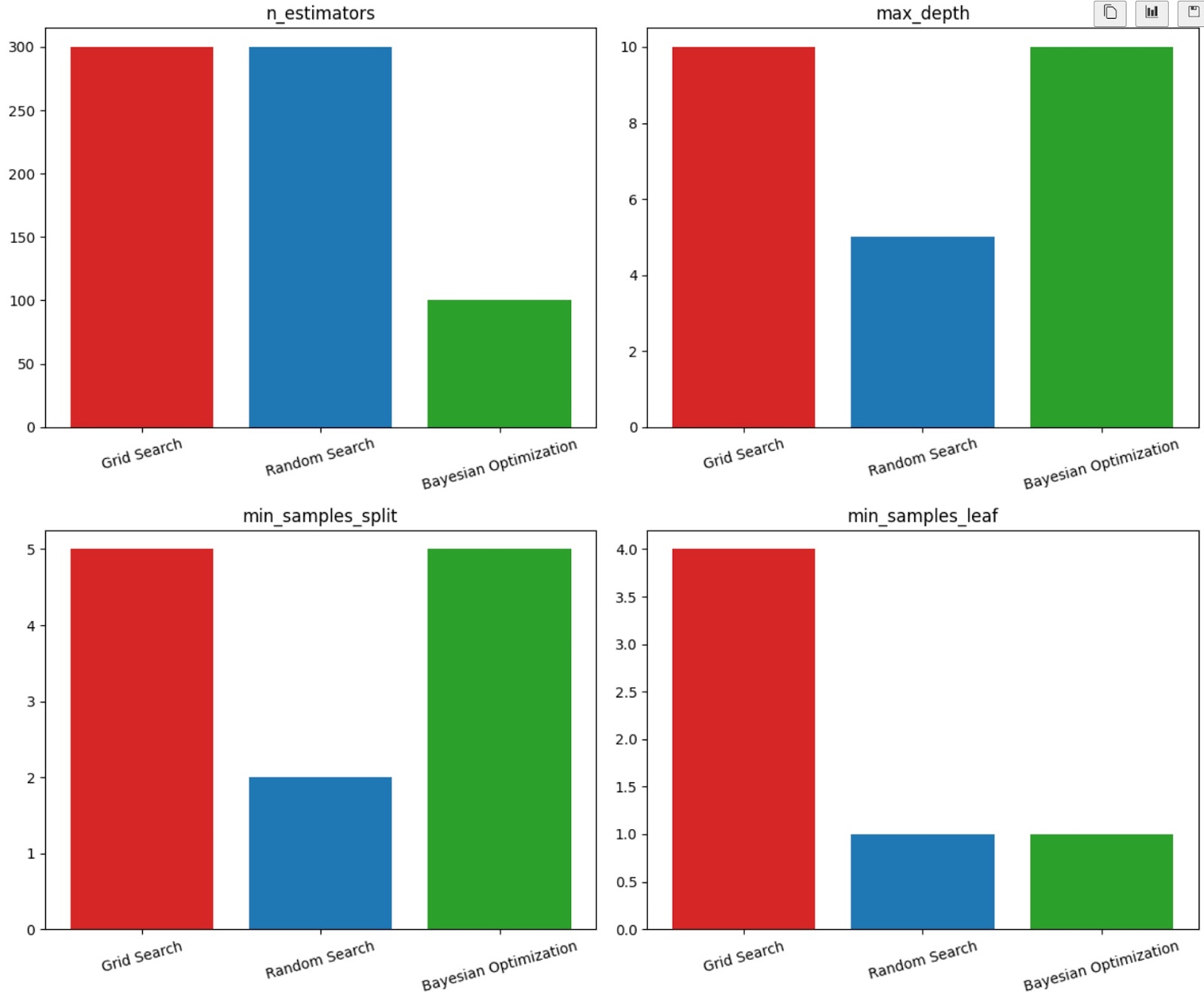
The plot provides a comparison of discussed hyperparameter tuning techniques. All three techniques seem to achieve similar levels of accuracy, with Grid Search potentially having a slight edge. Here you might see that the Bayesian Optimzation has taken larger time but Random Search and Bayesian Optimization are significantly faster than Grid Search, especially for larger search spaces.
Key Observations:
- n_estimators: All three techniques tend to select a relatively high number of estimators, indicating that a larger ensemble improves performance.
- max_depth: Bayesian Optimization and Random Search tend to select deeper trees compared to Grid Search, suggesting that deeper models might be more effective for this specific dataset.
- min_samples_split and min_samples_leaf: There is more variation in the selected values for these hyperparameters.
Deciding Hyperparameters and Their Values
The first step in determining hyperparameters and their values is to understand the specific model you’re using and the nature of your data. Factors like:
- Model Complexity: A complex model might have more hyperparameters and a wider range of values.
- Dataset Size: Larger datasets might benefit from more complex models and longer training times.
- Computational Resources: The available computational resources will limit the number of hyperparameters and the range of values you can explore.
With time and experience, you’ll develop a strong intuition for selecting the right hyperparameters and their value ranges. Remember, the best way to improve your hyperparameter tuning skills is through practice and experimentation.
The Next Step
Remember, hyperparameter tuning is an iterative process. Experiment with different techniques, evaluate the results and refine your approach. By carefully considering factors like model complexity, dataset size, and computational resources, and by leveraging techniques like grid search, random search, and Bayesian optimization, you can significantly improve the performance of your machine learning models. To delve deeper, consider exploring KerasTuner, Scikit Optimize, Scikit HyperOpt, and Udacity’s catalog of machine learning courses and Nanodegree programs.
Stay Healthy, Stay Udacious!



