Introduction
We’ve made incredible advances in data science and AI since the last election, but those advances have not helped us better predict the US Presidential election. Despite over 800 US election polls conducted since the beginning of September, there is no certainty on what the outcome of the election will be on Tuesday. As ABC News recently reported, the election is a “normal polling error” away from a blowout.
So, how do you make sense of the polls? How do you know which polls to trust? What do the results even mean? In this article, we unpack the data science behind the polling to shed some light on this complicated process and give you the tools to better understand how the various election predictions are made. In this article we will:
- Provide an overview of how election predictions and polling work
- Unpack how polls and predictions slice the data to provide more clarity
- Review margin of errors’ impact on the predictions and how that should be interpreted
- Rate the pollsters
- Discuss how data scientists simulate the outcomes based on the polls
- Introduce how rule-based models fit into this space – and can be effective
- Share how AI and ML techniques are used to better predict outcomes
Sampling: The Foundation of Election Polling
Election predictions are based on polling data. Pollsters contact individual people to ask them election-related questions. Historically, this was almost exclusively done via live phone calls, but recently, online polling has become more popular.
But how do pollsters manage to estimate how various groups are going to vote, without calling or emailing every single person in the country? The answer is sampling. Pollsters use information about statistical distributions combined with probability theory to determine the number of people to poll as well as to choose which individuals to contact.
“Probability-based” online polling is a particularly trendy technique because it combines random sampling with an online polling data collection format. Pollsters start by randomly selecting individuals based on phone numbers or postal mailing addresses, then direct them to an online form to complete the actual polling questions. Pew Research has found that “opt-in” online polls, which do not use probability-based sampling, are about half as accurate as probability-based online polls.
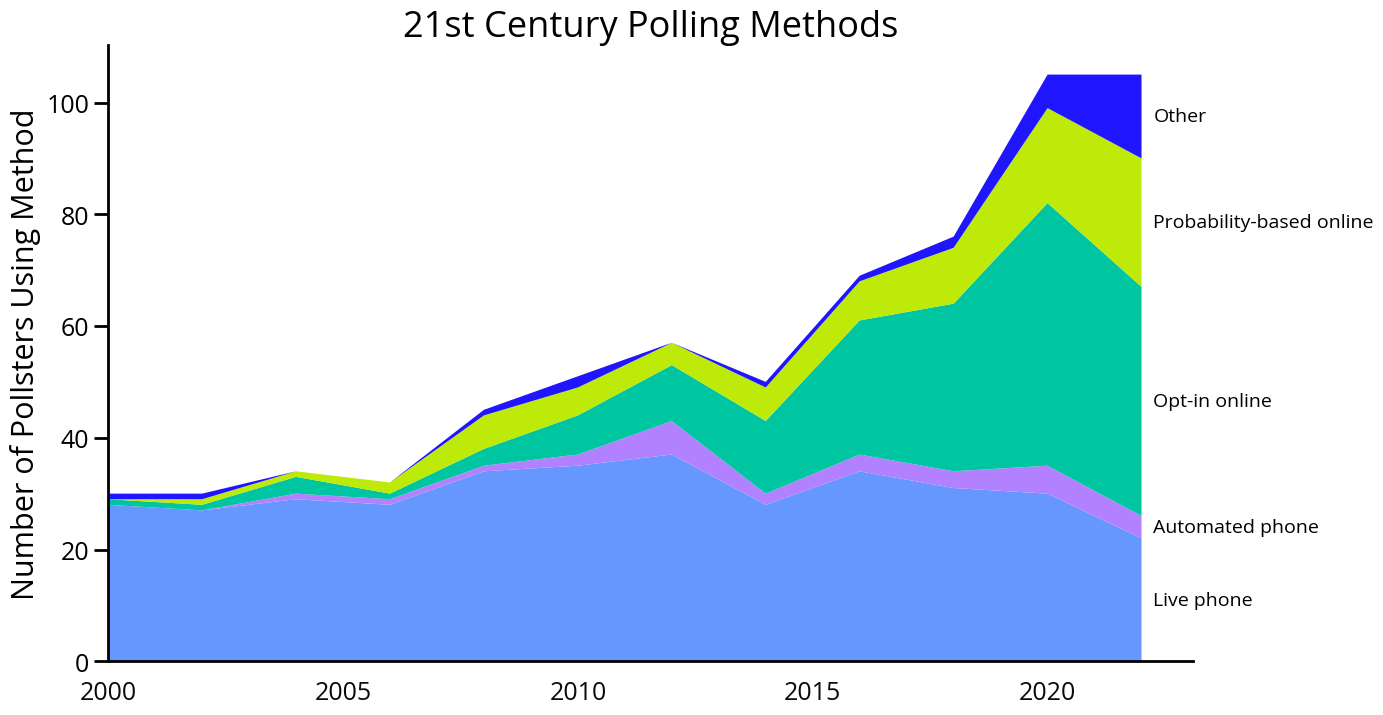
Data Source: Pew Research Center, “How Polling Has Changed in the 21st Century”
Slicing the Data: Visualizing Polls with Small Multiples
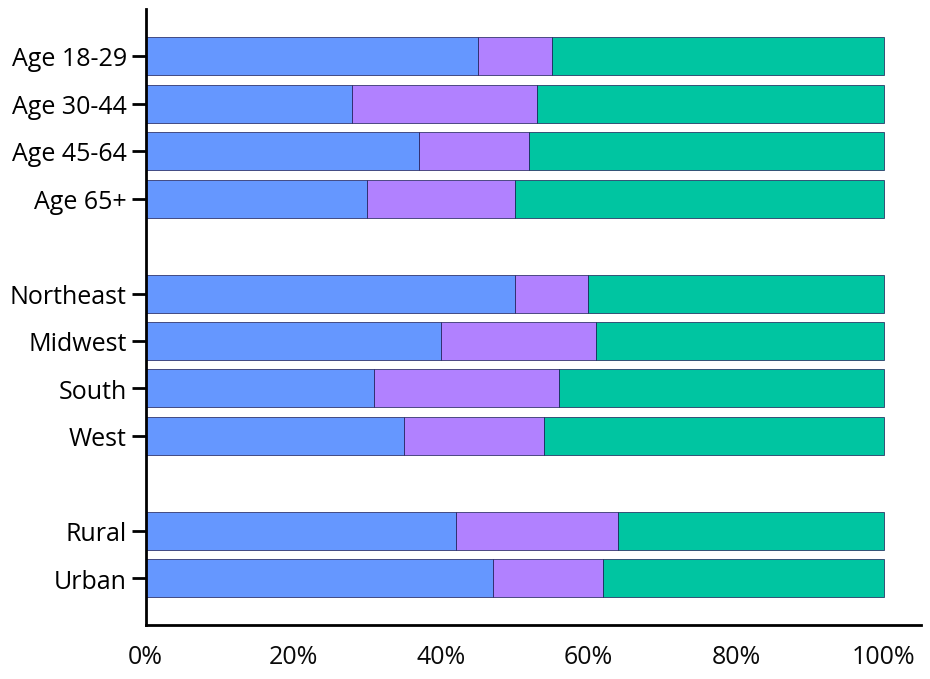
When reporting the findings from a poll, pollsters or other election watchers typically start with a high-level summary statistic. For example, 45% of likely voters support Candidate A. However, some of the most interesting results can come from breaking down the polling data into various categories, such as age, gender, or geography. These categories can help to get a more accurate picture of upcoming elections, especially in countries like the United States, where candidates are not elected directly but rather through an aggregation system like the Electoral College.
A “small multiples” visualization is a popular way to visualize the differences between these categories. This visualization displays a series of graphs using the same scale and summary statistic formula to enable visual comparison between groups. This graph shows an example using made-up polling data with three possible responses split by age and geography.
Understanding Polling Errors: The Margin of Error and Why It Matters
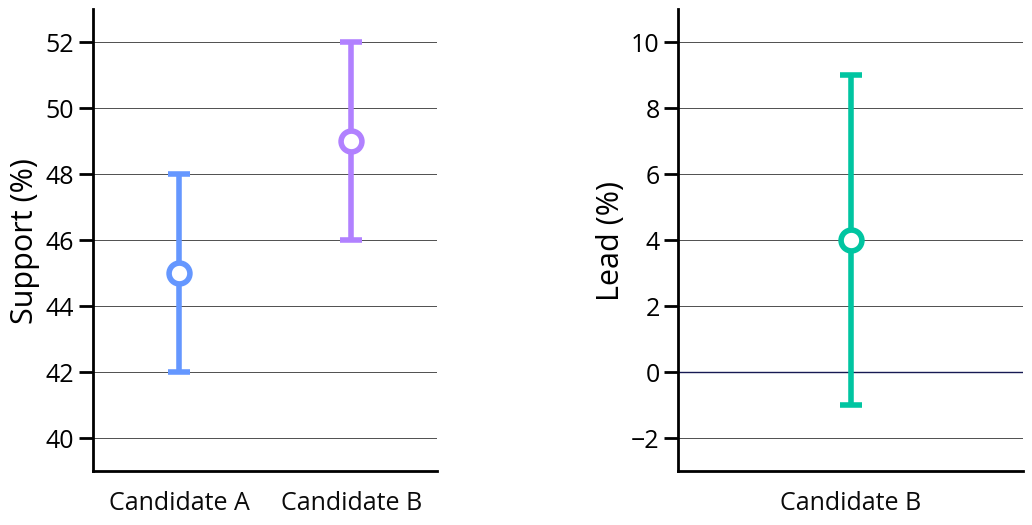
A single answer like 45%, or even a small multiples plot, conceals a more subtle aspect of polling: the margin of error. Because polls only cover a sample of the population, there is always inherently some amount of uncertainty in translating the polling results from the sample to the projected value for the whole population. The margin of error reports this uncertainty in the format “±3” or “+/- 3”, both of which are pronounced, “plus or minus three”. This means that the pollster analyzed the variance within their sample and determined that the true value is likely within the range from three below the reported value to three above it. So, for our 45% example, that means the true value is likely between 42% and 48%. This range, from 42-48%, can also be referred to as a confidence interval. Each pollster differs on their exact methodology, but they typically apply a 95% confidence level, meaning that 95% of the time, the true value is expected to fall within the reported range.
The margin of error calculation is also dependent on the specific measure being estimated, as Pew Research explains. Let’s say we are polling people to determine whether they support Candidate A or Candidate B. The result is 45 ± 3% for Candidate A and 49 ± 3% for Candidate B. Overall, this means that Candidate B has a 4-point lead because 49-45=4. If we changed the measure to Candidate B’s lead, rather than Candidate B’s support, it would most likely not be 4 ± 3. This is because estimating the lead involves combining two separate estimates, each with its own sampling variability, which requires a different calculation and usually results in a larger margin of error, e.g. 4 ± 5. For this reason, you might hear the same polling result reported as both “Candidate B leads the polls with 49% of the vote, ± 3%” and “Candidate B leads the polls by 4 percentage points, ± 5”.
Rating the Pollsters: Which Polls Should We Trust?
So, the pollsters self-report their margins of error, but can we trust them to report accurately? Also, many polls are run by politically partisan organizations and, therefore, might ask their polling questions in a way that skews the results. How can we anticipate their biases? In response to these questions, journalists at the website 538 created a database of pollster ratings. First, they calculate the error of each pollster, which is based on the difference between the polling results and the actual election results. It is adjusted based on the reported margin of error as well as external factors such as the type of election and the error of other pollsters in the same election. They also calculate the bias of each pollster, which is based on the partisan skew. This plot shows some examples of the pollsters rated by 538 and their various bias and error scores. Note that the statistical adjustments mean that the best pollsters actually have negative bias and error scores. This means that these pollsters have less bias and error than their peers, meaning that their polling results are the most trustworthy.
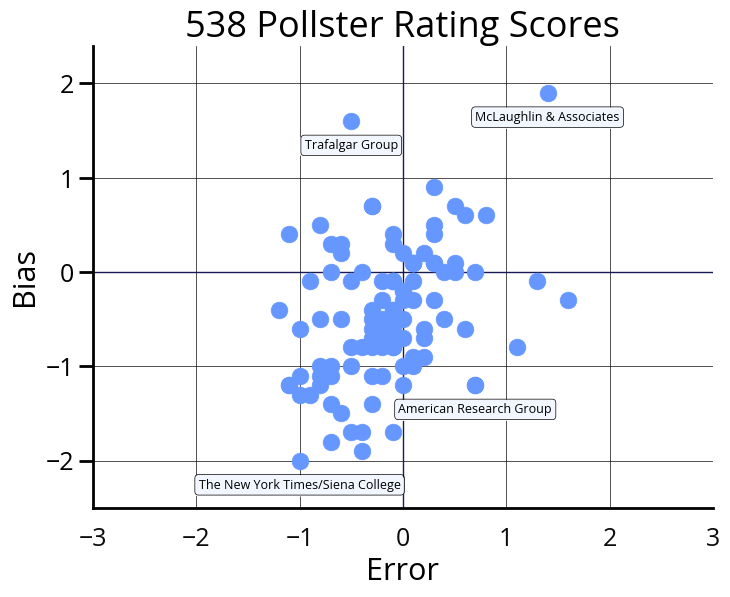
Data Source: 538 Pollster Ratings, Retrieved October 2024
Simulating the Vote: How Statistical Models Use Bootstrapping
The reason that organizations like 538 calculate these scores is so that they can feed them into statistical models that predict the outcomes of elections. The underlying algorithms behind these models are typically proprietary, but they almost always include some form of bootstrapping. Bootstrapping is a statistical technique that attempts to estimate values through simulations. Using the polling data and various error scores, their code simulates possible outcomes and then makes a prediction based on aggregating those outcomes.
Political polls themselves are not the only possible inputs to these types of models. For example, 538 also calculates a transparency score for each pollster based on a questionnaire about their techniques. Statistical modelers also might incorporate data about the economy, consumer sentiment, or even betting markets.
This plot shows an example of possible outcomes of bootstrapping with 150 simulations, where each simulation is represented by a circle. Graphing the distribution like this gives a better sense of the possibilities than simply summarizing the aggregated prediction—in this case, Candidate B has a 57.3% chance of winning.
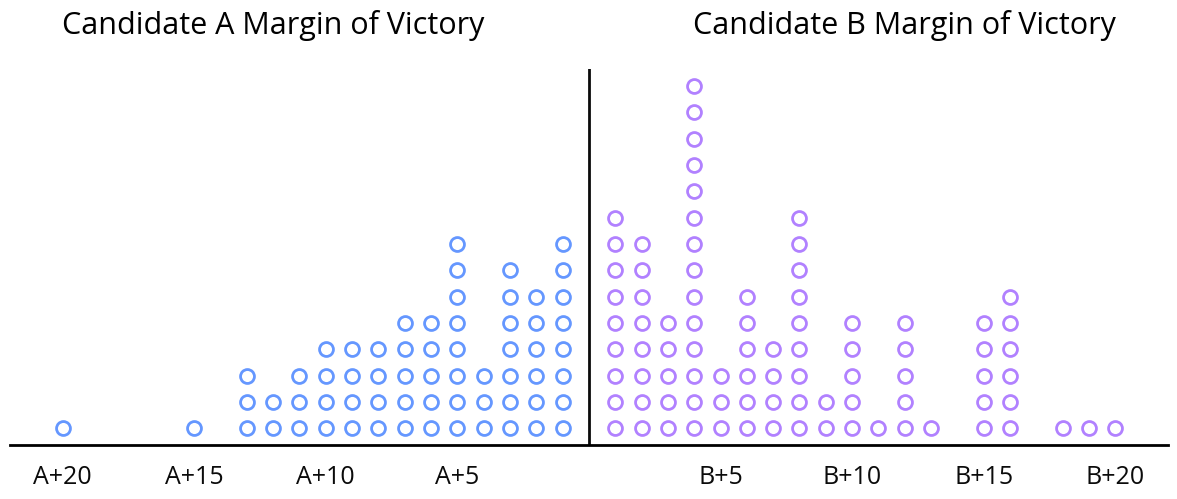
The “13 Keys” Model: Rule-Based Predictions in Elections
Despite all of these fancy statistical techniques, you may have observed that election prediction models are making more and more mistakes lately. Many polls are getting response rates around 1%, not true random samples of the population, and political scientists are currently debating whether or not it’s possible to correct this imbalance using statistics.
One alternative approach to making election predictions is to use a rule-based model, also known as fundamental analysis (named after similar techniques applied in stock trading). Instead of relying on statistical transformations of polling data, rule-based models incorporate high-level factors about the election. The most famous of these models is the “13 Keys” model developed by American University professor Allan Lichtman. This model has 13 true/false questions, and if 6 or more answers to those questions are false, it predicts that the incumbent party (the party currently holding the presidency) will lose. Dr. Lichtman developed this model in 1981 and reports that it has correctly predicted every American presidential election for the past 40 years!
Although it is rule-based, this model does not avoid data science altogether. For example, key #4 is there is no significant third-party or independent campaign. Essentially all American presidential elections have at least one declared candidate who is not part of either major party, but key #4 is only true if that candidate is polling at 10% or higher. On the other hand, some keys are solely based on qualitative political science analysis, such as the incumbent administration effects major changes in national policy and the challenging-party candidate is not charismatic or a national hero.
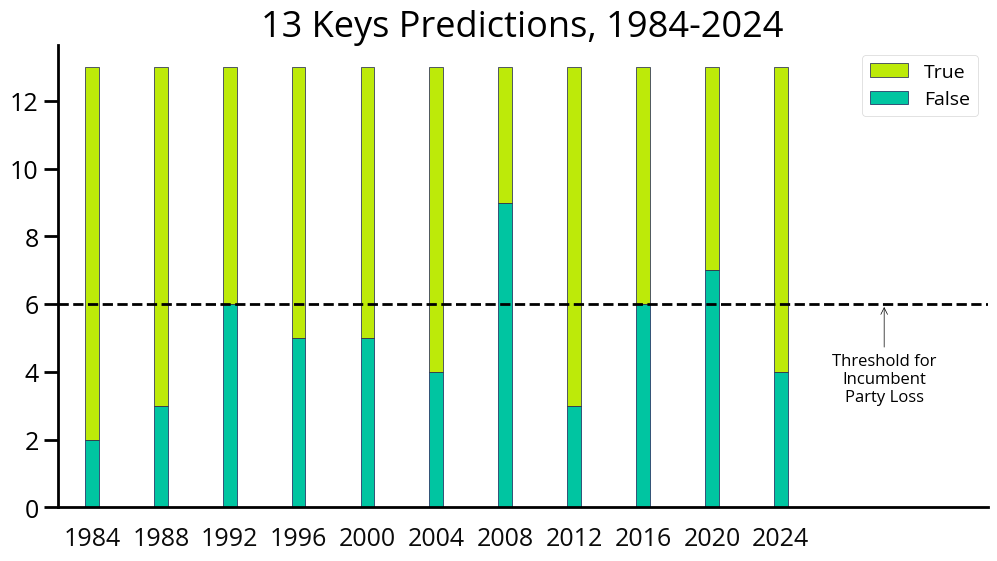
Data Source: Publications of Allan Lichtman, Aggregated by Wikipedia
AI in Elections: Predicting Outcomes with Machine Learning
In other industries and disciplines, from credit approval to spam detection, data scientists typically use machine learning (ML) models instead of rule-based models. However, we are still in the early stages of applying ML to election predictions. In machine learning, an algorithm is used to generate rules for predicting the outcome, and the resulting rules are almost always more complex than a series of 13 true/false questions. In a linear model, for example, the algorithm might determine that an increase of $1 per gallon in gas prices leads to a 2% reduction in the popularity of the incumbent party. Or, in a tree-based model, the algorithm might determine that the combination of 5% inflation, increased voter ID laws, and $100 million in campaign spending for Candidate A leads to a 4% increase in Candidate B’s margin of victory. Even more complex models, such as neural networks, create such elaborate internal rules that they are often referred to as “black boxes”—data scientists input features, and the model produces predictions, but the exact decision-making process is opaque.
While it may seem like these models should perform better than the statistical models or rule-based models, because they can capture so much more complexity, the major challenge in using machine learning for election prediction is actually a lack of data! There are numerous input features that can be fed into these models, from economic data to complex natural language processing (NLP) analyses of the words candidates use in their speeches. But the prediction target data—the winning candidate in a classification setup, or margin of victory in a regression setup—is relatively scarce. In the United States, presidential elections are only held every 4 years, totaling fewer than 100 elections in the history of the country, and the relationships between the input features and the prediction target shift over time as the political parties and voter demographics have changed. Most machine learning algorithms require thousands of examples to learn enough to make accurate predictions, meaning that this is a “small data” problem on the frontier of machine learning techniques.
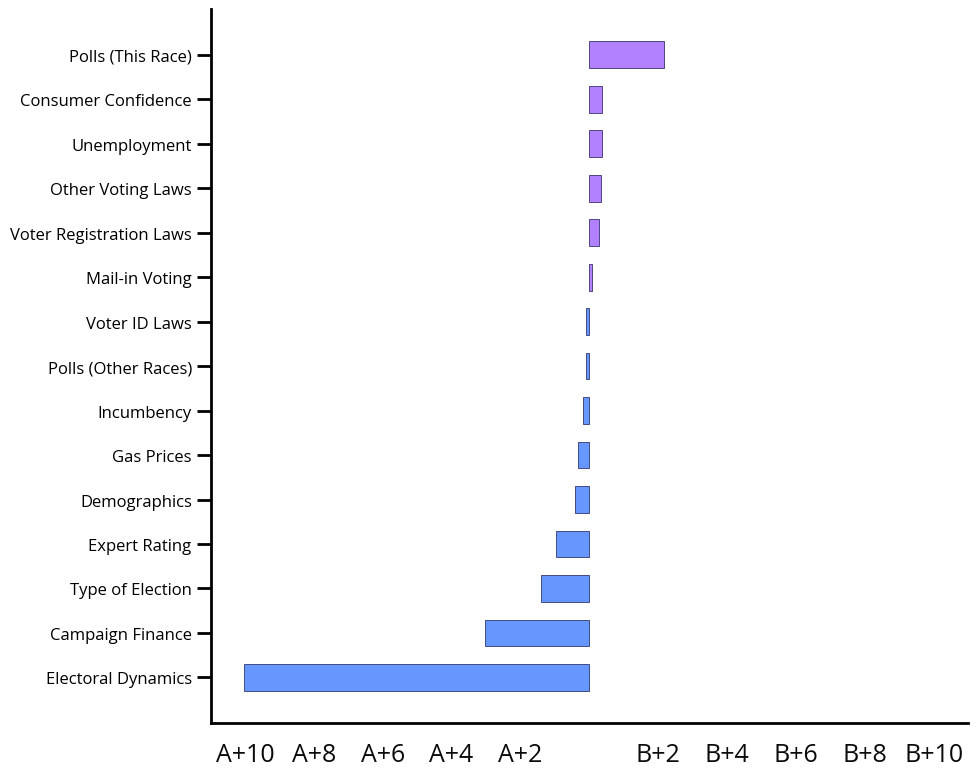
Let’s take a look at an adapted version of the results from tree-based models developed at Brown University. In order to make the underlying rules more interpretable, these researchers applied a model interpretability technique called SHAP (Shapley Additive Explanations), which uses game theory to extract information about the impacts of different features on the prediction target. This example plot shows that polls are pushing the model farthest in favor of Candidate B, while electoral dynamics are pushing the model farthest in favor of Candidate A.
Conclusion
As you can see, election predictions rely on a wide variety of data science techniques, from basic sampling and data collection to advanced models. Experts disagree on whether the best models are statistical, rule-based, or ML-based—each approach has pros and cons. Only time will tell which approach will win out! But regardless of the approach, data science is an essential component.If you’re interested in learning more about how to apply these techniques yourself, check out Udacity’s Statistics for Data Analysis, Data Analyst, and Data Scientist Nanodegree programs.


