Last Updated on October 23, 2024
The internet accumulates mind-boggling amounts of data daily — amounts in the petabytes, exabytes and zettabytes.
As data continues to accumulate, we’re seeing increased demand for efficient data processing, storage and transmission.
In this article, we’ll cover serialization, a process that enables and facilitates the handling of high-level data objects in Python.
What is Serialization?
Serialization is the process of converting a data object from its original in-memory structure into a binary or text-based format. Serialized objects can later be deserialized — or deconstructed — from their serialized form. Serialization is so essential to programming tasks that most of the popular programming languages include it in their standard libraries.
Why Do We Need Serialization?
Serialization allows you to save, send and receive data while maintaining its original structure. You might find that useful for saving certain data in a database and reusing it later, or for transmitting data over a network and accessing it on a different system.
Serialization has also proved very useful for data science projects. For example, preprocessing a dataset is often time-consuming, so preprocessing the data just once before saving it to disk is preferred to preprocessing it each time you’re going to use it. Serialization also alleviates memory limitation issues for data too big to be loaded into memory in one piece. By splitting the data into smaller chunks, you can load each chunk for preprocessing, saving the results to disk and then removing the chunks from memory.
The next two sections cover the two data serialization formats: text serialization and binary serialization.
Python Serialization: Text-Based Formats
Textual serialization is the process of serializing data in a format that’s human-readable and easily inspected. Text-based formats are typically language agnostic and can be created with any programming language. The following two sections cover two popular text serialization formats: JSON and YAML.
JSON
JSON is the standard format used for exchanging data between web clients and servers. Placing readability above all else, JSON serializes objects in plain text files, allowing for easy visual examination. JSON hierarchically stores objects in terms of key-value pairs, much like a Python dictionary.
Python’s built-in JSON library makes working with JSON data a breeze. We’ll see how in the following example, where we’ll use Python to perform JSON serialization on a data record describing a person.
JSON serialization is as simple as creating the JSON file and dumping the object to it with the dump() method. In practice, dump() receives two arguments: (i) the object we’re serializing and (ii) the file that stores the serialized object.

json’s dumps() method returns a string representation of the serialized object, which we can use to explicitly write to a file:

Both of these methods create an identical JSON file, pictured below. However, keep in mind that dumps() can cause significant memory overhead when working with large files since this method loads the entire JSON string into memory before writing it to the file.

To deserialize JSON files into Python objects, json provides load() and loads() methods. Here’s how these can be used:

load() deserializes json files, whereas loads() deserializes JSON strings.

YAML
YAML Ain’t Markup Language (YAML) is a superset of JSON made to be more readable. YAML’s most important distinguishing feature is its ability to reference other objects within the same file. Another advantage is the possibility of writing comments, a feature that’s proved useful for working with configuration files, for example.
We’ll now use two Python objects and serialize them into a YAML stream.

The yaml library provides a dump() method for serialization and the syntax is the same as in the json library — but make sure to use the correct file extension, whether .yml or .yaml. Here’s an example:

The saved YAML file looks like this:

Note how YAML, like Python, uses indentation to show the data’s hierarchical structure. Key-value pairs are separated with a column, whereas a list chart’s elements use hyphens, with one element per row. This results in a format that’s much more readable than the JSON file we created in the previous section.
Indeed, deserialization is as simple as one method call:

We’re able to confirm that the file has been properly reconstructed back into a Python dictionary by checking the deserialized object’s type:

Python Serialization: Binary Formats
Binary serialization formats are not human-readable, but they’re generally faster and require less space than their text-based counterparts. Below we cover some of the most popular binary formats.
Pickle
Pickle is the most popular Python serialization format and is used for serializing almost all Python object types. Pickle is a native Python serialization format, so if you plan to serialize Python objects that you expect to share and use with other programming languages, be mindful of potential cross-compatibility issues. Here’s an example of object serialization with pickle:

Note that we use the “b” flag when reading and writing to binary files to let Python know that it should treat such files as a binary stream.
NumPy
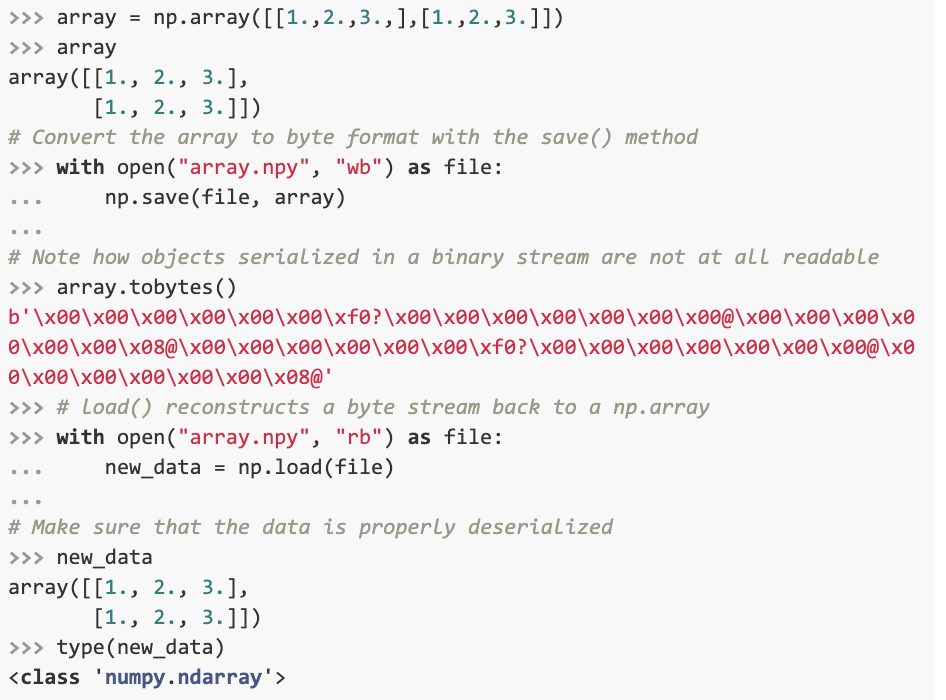
NumPy is a Python library used for working with large, multidimensional arrays and matrices. In the example below, we use numpy’s load() and save() methods to serialize a numpy array into .npy format.
Honorable Mention: HDF5
Hierarchical Data Format v5 (HDF5) is a file format used for storing datasets in a binary format. HDF5 stores rather than serializing data, whereas Python packages (e.g. PyTables and h5py) provide an interface for accessing and manipulating HDF5 files, allowing such files to be used as if they were real pandas DataFrames or numPy arrays. HDF5 is efficient at storing and manipulating huge amounts of data, which is why it’s become very popular in data science.
Keep Learning
Congrats! You’re one step closer to tackling complex data-heavy tasks on your own. But being able to serialize objects in Python is just the start. To continue learning, check out our Introduction to Programming Nanodegree to land that role as a web developer, data scientist or AI engineer.

