Last Updated on August 22, 2025
Ever had a conversation with an AI where it forgot what you said two minutes ago? Or even worse, gave you the exact same answer you already corrected?
And every time it happens, it reminds me why memory isn’t optional for agents. It’s not just a feature. It’s foundational. Without memory, your agent is basically a goldfish with a ChatGPT wrapper. If your agent can’t remember, it can’t improve. It can’t adapt. It can’t grow.
I’ve been building agent systems for a while now. And if there’s one thing I’ve learned, it’s this:
| Stateless agents might be clever, but they’re not useful for long. |
Let’s talk about what memory really means in this context and why it should be one of the first things you design when building your own agent system.
Not all memory is the same
We throw around terms like “short-term” and “long-term,” but honestly, those don’t fully capture what’s happening under the hood. It’s not just about how long something is remembered, it’s about why, how, and when.
So here’s how I like to think about it: memory types aren’t defined by time, but by scope and context.
That’s why I created the framework SAGE (State, Active, Growth and External). Let’s break it down…
State: What’s happening right now?
State is the agent’s internal working memory during a single execution. Think of it like a backstage pass. I mean, you don’t see it from the outside, but everything important is happening there. Tool calls, reasoning steps, retrievals, even persistent memory lookups. They’re all part of this transient context.
Once the execution ends? This state is gone. It normally doesn’t persist across runs. But while the agent is “thinking,” it’s everything.
If you’ve used ChatGPT and wondered how it comes up with a response, this is what’s going on in the middle. The user’s message is a trigger. The response is the output. The trajectory between those two is the execution state: snapshots of each step during transitions scoped by run ID.
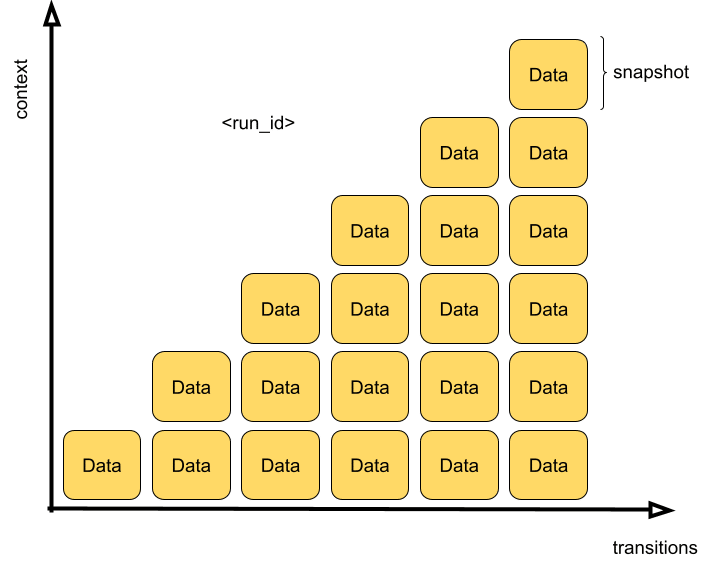
Context builds up with each transition
the more steps, the more data it carries forward within the same execution
And here’s the kicker: most of the time, the user doesn’t get access to this. It’s invisible. But as a developer, you can and should track it. That’s where observability comes in, but that’s a topic for another time.
Logs, traces, snapshots… whatever you use to debug your agent’s behavior, this is the data you’re tracking. Execution state is where you catch bugs, analyze failures, and understand what your agent is actually doing behind the scenes.
In my builds, I’ve found that good observability into state is often the difference between “works once” and “works reliably.”
A recommendation? Pick an agent (agentic workflow) creation framework that allows you exactly that.
Active: Let’s finish this conversation!
Active or short-term memory helps the agent keep track of what just happened from one turn to the next within the same session or thread. It’s not really about time, though. The next turn could happen in one second or ten days. What matters is that it’s still part of the same conversation scope.
If you’re building conversational agents, this is your best friend. It’s what lets the agent say: “As I mentioned earlier,” without sounding like a complete fraud. It stitches together multiple executions so the interaction feels human, not robotic.
And how does it work? Usually through something like a session ID. The memory is scoped to that session, meaning once it ends (or times out), the memory goes with it.
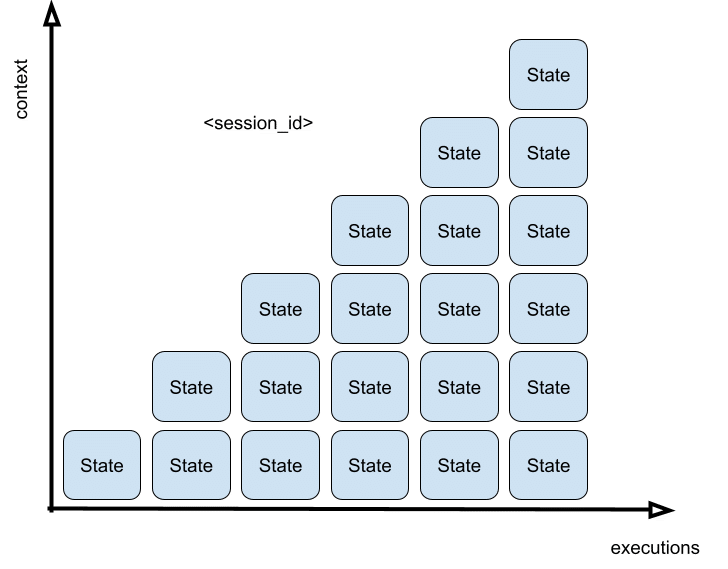
Context builds up with each execution
the more turns, the more state it carries forward within the same session
Ever chat with an assistant that suddenly forgot what you were talking about halfway through a conversation? That’s what happens when short-term memory is missing or broken.
Ah, the session ID I mentioned above is normally applicable to a particular user ID. It would be strange if it continues with you a session that started with me. But it really depends on the application.
For example, ChatGPT lets you continue old conversations because it persists every session it’s already had with you. However you can’t jump into my conversations with it.
Anyway, this isn’t about tracking every tool call or internal step (that’s state). This is about remembering the previous inputs, outputs, and goals across turns. It gives your agent context; and users, continuity.
Where it really shines is in follow-ups:
💬 “What about that second option you mentioned?”
💬 “Can you rewrite the last part, but more formal?”
💬 “Let’s change the destination to Rio de Janeiro.”
Basically:
- With no short-term memory? These are dead ends.
- With it? The agent stays in the flow.
In my experience, this kind of memory is often implemented as a structured list of recent interactions: compact, summarized, maybe even filtered to remove noise. Keep it lightweight, but smart.
| Just like us, agents don’t need to remember everything. They just need to remember what matters. |
Mind the token cost!
Growth: The story of my life
Growth or long-term memory is where agents start to feel personal. It’s the kind of memory that sticks around across sessions, projects, or even devices. It knows your preferences. Your goals. Events. It remembers that you prefer markdown. That you asked about climate policy last week. That you always choose Zoom over Meet. And that you hate PPTs.
But let’s be clear, this memory isn’t just about storing random facts. It’s about capturing persistent signals that help personalize the experience over time.
Most implementations scope this by something like an user ID, and they persist structured or semi-structured records: preferences, recurring goals, behavioral patterns, facts, etc.
| Long-term memory isn’t everything you said. It’s what matters enough to keep. |
A well-designed agent is autonomous enough to decide when to capture those signals and when to surface them as part of its context to achieve a goal. For example recalling you prefer Markdown when formatting the response.
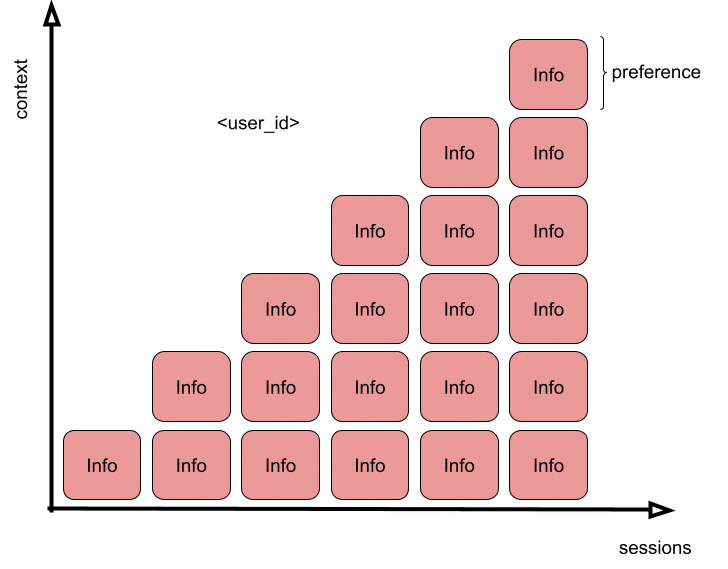
Context can build up with each session
the more signals captured during sessions, the more personalized the agent can be
Where things get complicated is what to do with it over time. This is not just a “write once, read forever” situation. It’s more like a living profile. If the agent can’t update outdated info; or worse, keeps acting on something that’s no longer true, you lose trust fast.
I mean, if you now prefer working with Python rather than Java, it should stop sending snippets of code in Java to represent computational concepts, right?
That’s where memory aging, summarization, and feedback loops come in. We’ll get into that soon, but for now: think of long-term memory as the foundation for agents that grow with you, not just respond to you.
And yes, it can get creepy if you don’t design it well. So design it well.
Personal tip? Store long-term facts as structured key-value pairs. Then add timestamps. That way you know not just what the agent remembers, but also how old that memory is.
Long-term memory turns an agent from a helpful assistant… into a familiar one.
But be aware that there are some agentic workflows (other than a personal assistant) that might require long-term memory as well.
For example a system that processes large volumes of tweets in order to identify funding transactions and the entities involved. It can learn which are valid items and which ones aren’t over time.
External: I don’t know, but I know where to look
External memory is an agent’s superpower, it’s the ability to look beyond itself. When the agent doesn’t have a fact in long-term memory, or the information is too vast, volatile, or even complex enough to be stored internally, it can retrieve what it needs. On-demand. From anywhere.
That might mean:
- Querying a vector store
- Searching your company wiki
- Looking up docs in S3
- Hitting a semantic index
You name it.
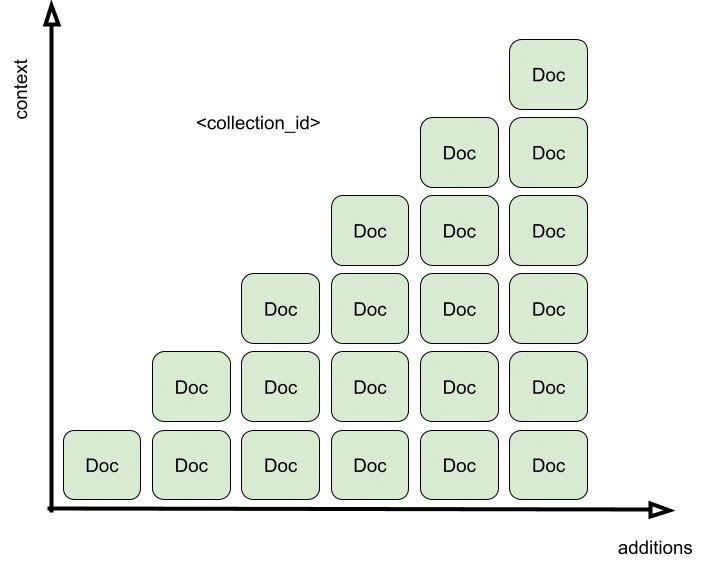
Context can build up based on external collections
This isn’t just about answering user questions, it’s about supporting reasoning, few-shot prompting, and procedural execution.
| External memory allows multiple agents to learn from one another indirectly. |
Let’s say one agent parses a product catalog, discovers a new price change, and stores a snippet in a knowledge store. Now other agents that come along later can retrieve that without ever having seen the original input.
It can be something even simpler like a white list or block list for e-commerce fraud contexts.
That’s powerful. But it also means you need to curate what gets stored. Otherwise, you end up with the famous “Garbage in, Garbage out”. Garbage retrievals are worse than no retrieval at all, as you’re probably guessing: they inject noise with confidence.
External memory should be queryable, updatable, and (when needed) removable. It’s not just a dumping ground. It’s a shared external repository, but you can call it a collective brain, just to coin a new buzzword.
Anyways, like any repository, it needs maintenance.
Memory Management
Okay. Let’s talk about the real work. Memory is EASY to add, but HARD to manage.
Especially as agents start stacking knowledge, sharing retrieval sources, and adapting across time. You need to decide:
- What gets saved?
- When does it get saved?
- Where does it go?
- How long should it stay?
- When should it be updated, summarized, or deleted?
This applies to both long-term and external memory, but in different ways.
For Long-Term Memory
This is user- or agent-specific knowledge. You want to track:
- Confidence in the fact (Was it inferred or explicit?)
- Recency (When was this last confirmed?)
- Relevance (Is this still useful or in use?)
- Feedback (Did the user correct or reinforce it?)
Some teams use embeddings to compare and merge facts. Others prune with decay rules (e.g. “delete unused facts after 60 days”) or summarize older threads into compressed knowledge chunks.
My 2 cents? Start simple. Store structured key-value pairs with timestamps and allow user override. Build from there.
For example, start simple with feedback loops. Man, this is crucial. Thumbs up/down, clarifications, or even implicit signals like rephrasing requests. All of that should be potential fuel for updating long-term memory, but only if you’re confident in the signal.
For External Memory
This is your multi-agent knowledge layer. The tricky part isn’t adding new content, it’s keeping it:
- Fresh (is this outdated?)
- Non-redundant (are there better examples?)
- Clean (is this hallucinated garbage?)
- Useful (can agents actually find and use it?)
You might need versioning. Expiration policies. Moderation workflows. Feedback signals (“this answer helped”) or usage frequency metrics.
I know I said that, but here I go again: not all data deserves to be remembered. Just because one agent retrieved it once doesn’t mean it needs to live forever.
Use Triggers, Not Only Timers
Forget “every 24 hours”? Hey, that’s lazy. Smart memory systems use triggers:
- Agent starts task → check if input from user should be saved
- Agent finishes task → check if outcome should be saved
- User provides feedback → reinforce or revise fact
- Fact hasn’t been used in last X sessions → consider summarizing
- Memory store exceeds size threshold → launch compression pass
- After Y sessions → review relevance of stored information
This approach makes your memory responsive, not just recurring. It also keeps latency low, relevance high, and weird surprises to a minimum.
Additional Concepts
If you’ve been around agentic AI circles, you’ve probably heard about mapping agent long-term memory types to human memory analogies: Procedural, Semantic, and Episodic. Blog posts pointing to papers like CoALA have quickly become the reference for anyone thinking deeply about agent memory design.

Source: Langchain blog
This framework is indeed super useful, especially when you’re trying to categorize or evaluate long-term memory needs. And it’s helped formalize the idea that agents can and should learn from interaction history.
But here’s the thing: It’s not enough to know these concepts. You need to build with the right ones.
And in real-world agentic systems, that usually means thinking in terms of:
- State (what’s happening right now)
- Active / Short-term (what’s happened in this ongoing interaction)
- Growth / Long-term (what’s been learned over time)
- External (what the agent can fetch on demand)
These aren’t just theoretical buckets, they’re design surfaces. They shape how your agent behaves, scales, and adapts.
I know what you’re thinking, now I am sounding like an LLM. But that’s only me trying to get a new concept off the ground.
Seriously, knowing what kind of memory your agent needs in order to be useful (and how to manage each type) is more important than mapping things to a cognitive model.
My rationale is simple:
- Human memory analogies (Procedural, Semantic, Episodic) are a lens
- But SAGE (State, Active, Growth, External) is the blueprint
For example, what if you want to provide to your agent information about users coming from a CRM application?
No matter if it’s semantic or episodic. You need to think about the scope (for example user ID), where you’re storing and how the agent will retrieve it. And again, how are you going to maintain it?
Final Thoughts
Well, memory isn’t just a module you plug into your agent stack.
It’s a living, evolving part of your system’s intelligence. It’s the difference between a prompt-based chatbot and a truly contextual AI. But if you don’t manage it, memory rots. It becomes noise. Or worse, false confidence.
So treat memory like you treat code: Test it. Trace it. Update it. And sometimes… delete it.
So before you build your next agent, ask yourself: What kind of memory does it need?
And just as important: how will you keep it sane?



