Last Updated on October 23, 2024
What’s the difference between fake data and synthetic data?
Fake data and synthetic data are both used to describe artificial data, but there are important differences. The differences lie in the characteristics, the uses, and the methods of generating the data.
The table below demonstrates some of these differences.
| Fake Data | Synthetic Data | |
| Characteristics | Random values but typically within normal ranges. | Values that have realistic joint distribution properties. |
| Uses | Usually used for testing of databases and software. | Used to augment real datasets for model training as well as ensure privacy. |
| Methods of generating | Often drawn from databases of values or randomly generated values. | Various machine learning methods can be used including generative adversarial models and variational autoencoders. |
When testing databases and software prior to releasing a system, no real data has been generated and yet it is important to test systems with more than just a few values. User interface testing and performance testing are incomplete without having realistic amounts of data in a system. This is where being able to generate large amounts of fake data quickly can be useful.
There are many resources available for generating fake data. Several are listed on Towards Data Science, some of which are services that generate data for you while others are software libraries. This article will focus on the Python Faker library and will cover several techniques that may be useful to get you started.
Creating fake data using the Python faker library.
Getting started using Python Faker is straightforward. Use your favorite package manager to install the Faker library then simply use the following statements to import the library and create a new Faker object and set a random seed:
from faker import Faker
fake = Faker()
Faker.seed(42)
Now you have an instance you can use to generate fake data. Setting the seed allows you to re-generate the same fake data. Changing the seed will give you different randomly generated values.
Standard Providers
Now that we have an instance, let’s generate some fake data using the standard providers from the Python Faker library.
from faker import Faker
fake = Faker()
Faker.seed(42)
#Addresses
print(fake.address())
print(fake.building_number())
print(fake.city())
#Emails
print(fake.ascii_company_email())
print(fake.ascii_free_email())
#People
print(fake.name())
print(fake.first_name())
print(fake.last_name())
print(fake.first_name_female())
#Social Security Numbers
print(fake.ssn())

You can see how easy it is to generate random values that would fit into typical fields in a database. There are many standard providers that can be used out of the box without any parameters to quickly and easily generate fake data.
Standard Providers with Ranges
Sometimes you need to generate values that fit within realistic ranges. For example, perhaps valid dates for a field are only dates from this century or this decade. Or perhaps valid dates are only in the past or in the future. Or maybe you need to automatically test a password input form and the randomly generated passwords need to conform to your organization’s password complexity rules.
The code below demonstrates some of the built-in capabilities of the standard providers that limit ranges of outputs while still generating random data.
from faker import Faker
fake = Faker()
Faker.seed(42)
#Dates within ranges
print(fake.date_this_century(before_today = True))
print(fake.date_this_decade(after_today = True))
print(fake.date_time_between(start_date = '-7d', end_date = 'now'))
#Passwords
print(fake.password(length=16, special_chars=True, upper_case=True))
print(fake.password(length=8, special_chars=False, upper_case=False))

Generating many rows of data
In the code above we have seen how to generate single values of various types of data using Python Faker. In a real scenario, we likely would want to generate many rows of data and since we are working in Python, we probably would want this data in a Pandas DataFrame. The code below relies on both Pandas and NumPy so if you haven’t installed these already in your environment, you will need to do so before running this code.
from faker import Faker
import pandas as pd
import numpy as np
Faker.seed(42)
def generate_persons(num = 1):
fake = Faker()
rows = [{
'person_id':fake.uuid4(),
'first_name':fake.first_name(),
'last_name':fake.last_name(),
'address':fake.address(),
'dob':fake.date_of_birth(minimum_age = 18, maximum_age = 75),
'ssn':fake.ssn()
}
for x in range(num)]
return pd.DataFrame(rows)
persons = generate_persons(1000)
print(persons)

You can easily modify this code to add different columns to the DataFrame that is returned from the function.
Generating data in more complex scenarios
If you want to generate more realistic data, you would presumably already have some data to inform your definition of “realistic”. In these situations, you will want to use synthetic data. But Python Faker can be used to generate data that conforms to simple rules and while not based on real data, can be made to look realistic.
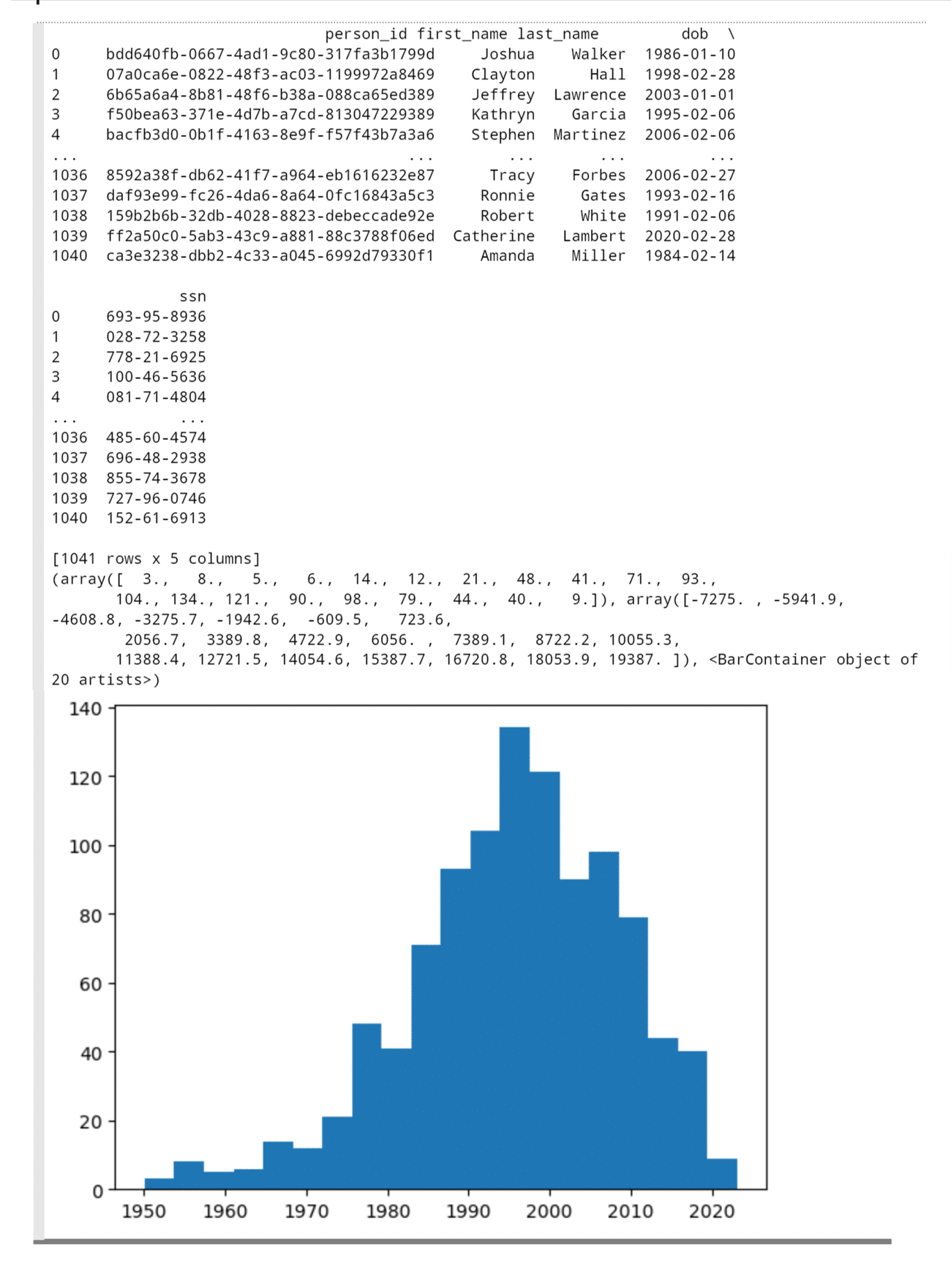
In the sample code below, we have modified the generate_persons method from above to generate dates of birth that represent a skewed set of data. We do this by generating the desired distribution of ages (mostly young) and then using a date utility function, relativedelta, to create birthdates. In addition, we randomly generate a Boolean that marks certain rows as duplicate rows and then use Pandas concatenation to add these duplicate rows. Both of these make the data look more like something you would see in a real-world environment. Note, the code below uses matplotlib to show the distribution of birth dates generated so you will need to make sure this library is installed in your environment before using this code.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from faker import Faker
from dateutil.relativedelta import relativedelta
fake = Faker()
Faker.seed(42)
def generate_persons(num = 1):
ages = ((np.random.beta(3,8, size=num+1)) * 100).astype(np.int32)
rows = [{
"person_id":fake.uuid4(),
"first_name":fake.first_name(),
"last_name":fake.last_name(),
"dob":fake.date_this_year() - relativedelta(years = ages[x]),
"ssn":fake.ssn(),
"DUP":fake.boolean(5)
}
for x in range(num)]
return pd.DataFrame(rows)
persons = generate_persons(1000)
persons = pd.concat([persons, persons[persons["DUP"]]], ignore_index=True)
persons = persons.drop(columns=["DUP"])
print(persons)
print(plt.hist(persons['dob'], bins=20))
Learn to code with Udacity
Generating fake data with Python Faker is a great skill for any data engineer. In this article, we learned the difference between fake and synthetic data and learned how to generate a variety of fake data using the Python Faker library. This is a powerful way of generating large amounts of data quickly that can be used to test user interfaces and databases.
Want to really take your data engineering skills to the next level?
Our Programming for Data Science with Python Nanodegree program is your next step. We’ll teach you how to work in the field of data science using the fundamental data programming tools: Python, SQL, command line, and git.


