
An important skill for any data engineer is ingesting data with Python. Python has become one of the most popular languages among data scientists which means a data engineer who develops skills with this language will be an asset to their team. The Python Pandas library contains a large variety of functions for manipulating data, including a broad set of tools for ingesting data.
In this article, we will review what it means to ingest data and then how to handle various data formats when ingesting data with Python using Pandas.
What is data ingestion?
Broadly, data ingestion is accessing and transporting data from a source or sources to a target. In the case of an Extract, Transform, Load (ETL) process, data ingestion is typically associated with the Extract step.
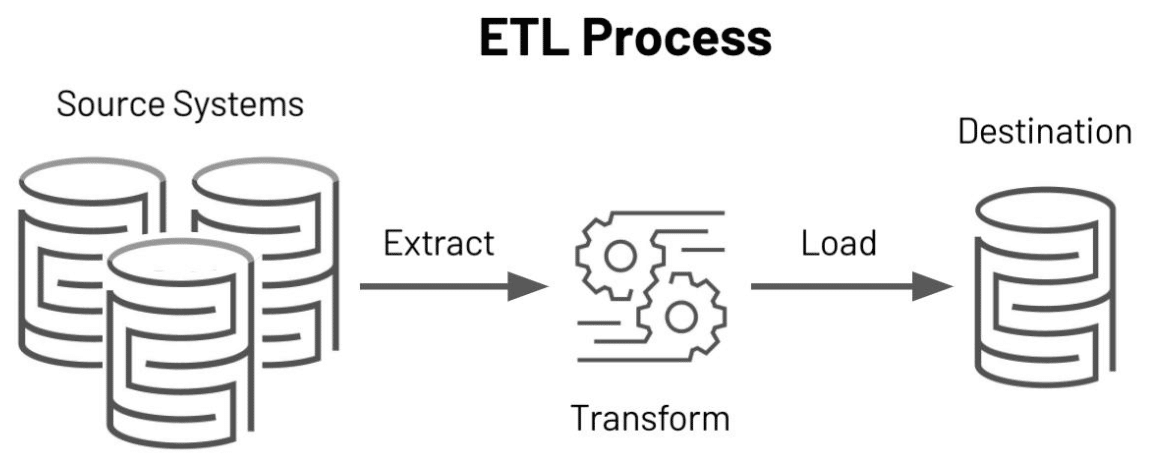
The target in this case is the Transform step where a set of data structures within Python hold the data being manipulated. Transformation of data plays a critical role in the success of any data science project so ingesting data efficiently and accurately lays a strong foundation for success.
How to ingest data with Python using Pandas.
A key insight for ingesting data with Python is recognizing that source data comes in various source formats such as a CSV, Excel, JSON, and Parquet files as well as SQL databases. One reason for using a library such as pandas is while the formats may vary considerably, the IO API does an excellent job of standardizing the syntax.
The generic format for the various data ingestion tools in Pandas follows the form:
read_x(source,…)
where x is the format being read and source is the location of the data followed by a variety of often optional parameters.
How to ingest data from different sources.
In the sections below, we will walk through some code examples using Pandas to ingest data from various data sources. Each section will have code you can run against a sample data file to demonstrate the ingestion.
For the exercises below, we will use data from the Kaggle datasets. You can download the water_quality_data.csv file from here but you can find the source data on Kaggle.
CSV Files
Example file: water_quality_data.csvCSV files are a very common format in the data science world. This format is a text file format with one line of text per row of data with the values in each column separated by a comma. The code to ingest a CSV file is given below:
# Ingest data from a CSV
import pandas as pd
df = pd.read_csv('water_quality_data.csv')This code imports the pandas package and uses it to read the CSV file into a variable called df. This variable is a pandas dataframe), one of the most popular table-like data structures in Python.
For an example of using different parameters to affect the way the CSV file is read, try downloading the file directly from the Kaggle website referenced above. The downloaded file uses a character encoding called CP-1252 but by default, the read_csv function uses UTF-8 and thus will produce an error if you try to use the code above to read the file. To correctly read this file (and save it out to the file you downloaded above), use this code (notice the encoding parameter):
import pandas as pd
df = pd.read_csv('Water_pond_tanks_2021.csv', encoding='cp1252')
df.to_csv('water_quality_data.csv', index=False)For reference, the code to generate all the files used in the sections below is:
import pandas as pd
import openpyxl
import pyarrow
from sqlalchemy import create_engine
df = pd.read_csv('Water_pond_tanks_2021.csv', encoding='cp1252')
# Write to various file formats
df.to_csv('water_quality_data.csv', index=False)
df.to_excel('water_quality_data.xlsx', sheet_name='water data', index=False)
df.to_json('water_quality_data.json', orient='columns')
df.to_parquet('water_quality_data.parquet', engine='pyarrow', index=False)
# Write to a SQLite file
engine = create_engine('sqlite:///water_quality_data.db')
df.to_sql('waterquality', engine)Note the additional dependencies on the openpyxl, pyarrow, and sqlalchemy packages.
Excel Files
Example file: water_quality_data.xlsx
Excel is a very popular software program from Microsoft that is often used by business users to collect data. Excel files (with the extension .xlsx) often have more than one sheet and are comprised of multiple files zipped together. Fortunately, using the openpyxl package reduces the complexity of working with these files and the code to read these files is as follows:
# Ingest data from Excel
import pandas as pd
import openpyxl
df = pd.read_excel('water_quality_data.xlsx', sheet_name='water data')Note the use of the sheet_name parameter in the call to read_excel which identifies which of the sheets you wish to open. You can also pass in None to ingest all the sheets or a list of sheet names to ingest specific sheets with a single file read.
JSON files
Example file: water_quality_data.json
JSON is another very popular format for storing and transmitting data. This format is often preferred by programmers and data professionals due to its succinct format that preserves human readability. The ubiquity of this file format among data professionals means it is well-supported in nearly all data engineering tools and Python is no exception. The following code will ingest a JSON file into a pandas dataframe:
# Ingest data from JSON
import pandas as pd
df = pd.read_json('water_quality_data.json')Parquet Files
Example file: water_quality_data.parquet
The parquet file format is an Apache Open Source column-oriented file format that is popular with big data applications. Whereas row-oriented formats like CSV keep all the data from a record or row together, column-oriented formats keep all the data from a field or column together. When handling large sets of data, it is useful to sometimes ingest only the data from relevant fields which is a feature column-oriented formats support well.
Parquet is not human-readable and instead is stored as a binary format. To view the data from a parquet file, you need a tool such as ParquetViewer.
The code to ingest data using Python from a parquet file is as follows:
# Ingest data from parquet
import pandas as pd
import pyarrow
df = pd.read_parquet('water_quality_data.parquet')Note the dependency here on the pyarrow package. This parquet file engine is the default for the read_parquet call but you can also use the fastparquet engine if you prefer. There are subtle differences but generally, pyarrow is preferred when using pandas dataframes.
SQL Databases
Example file: water_quality_data.db
The last data format we will cover is the SQL database format. For this article, we will use a SQLite3 database but with the appropriate connectors, similar syntax will work with many other relational databases including Postgres or MySQL.
The code to ingest data with Python using SQL is as follows:
# Ingest data from SQL
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('sqlite:///water_quality_data.db')
df = pd.read_sql('waterquality', engine)Note the use of the create_engine call which explicitly connects us to the SQLite3 connector. This is where you can use other types of connectors to connect to various SQL databases. See the SQLAlchemy documentation regarding dialects if you are using other databases.
Learn to code with Udacity.
Ingesting data with Python is a critical skill for any data engineer in a modern data science environment. In this article, we explained what it means to ingest data and then we explored different methods to handle various data formats.
Ready to take your data engineering skills to the next level? The Programming for Data Science with Python Nanodegree program is your next step. You’ll learn how to work in the field of data science using the fundamental data programming tools — Python, SQL, command line, and git.



