Lesson 1
Data Extraction Fundamentals
Review the fundamentals of tabular data formats CSV and Excel and learn about the JSON format.

Course
Data Scientists spend most of their time cleaning data. In this course, you will learn to convert and manipulate messy data to extract what you need.
Data Scientists spend most of their time cleaning data. In this course, you will learn to convert and manipulate messy data to extract what you need.
Last Updated March 7, 2022
Prerequisites:
No experience required
Lesson 1
Review the fundamentals of tabular data formats CSV and Excel and learn about the JSON format.
Lesson 2
Gain experience working with .csv files and wrangling JSON.
Lesson 3
Start working with XML and learn how to use BeautifulSoup to scrape web pages.
Lesson 4
Practice working with XML and parsing HTML with BeautifulSoup.
Lesson 5
Learn about what can make data "dirty" and find out how you can audit your data for quality.
Lesson 6
Practice auditing and cleaning dirty data.
Lesson 7
Find out how to use MongoDB to store and query your data.
Lesson 8
Practice wrangling data and inserting data into MongoDB.
Lesson 9
Learn how to create more sophisticated MongoDB queries using pipelines and operators.
Lesson 10
Gain experience with MongoDB pipelines and operators.
Lesson 11
Go through a case study showing how to audit, clean and prepare OpenStreetMap data for insertion into a database.

Instructor

Instructor
Combine technology training for employees with industry experts, mentors, and projects, for critical thinking that pushes innovation. Our proven upskilling system goes after success—relentlessly.

Demonstrate proficiency with practical projects
Projects are based on real-world scenarios and challenges, allowing you to apply the skills you learn to practical situations, while giving you real hands-on experience.
Gain proven experience
Retain knowledge longer
Apply new skills immediately
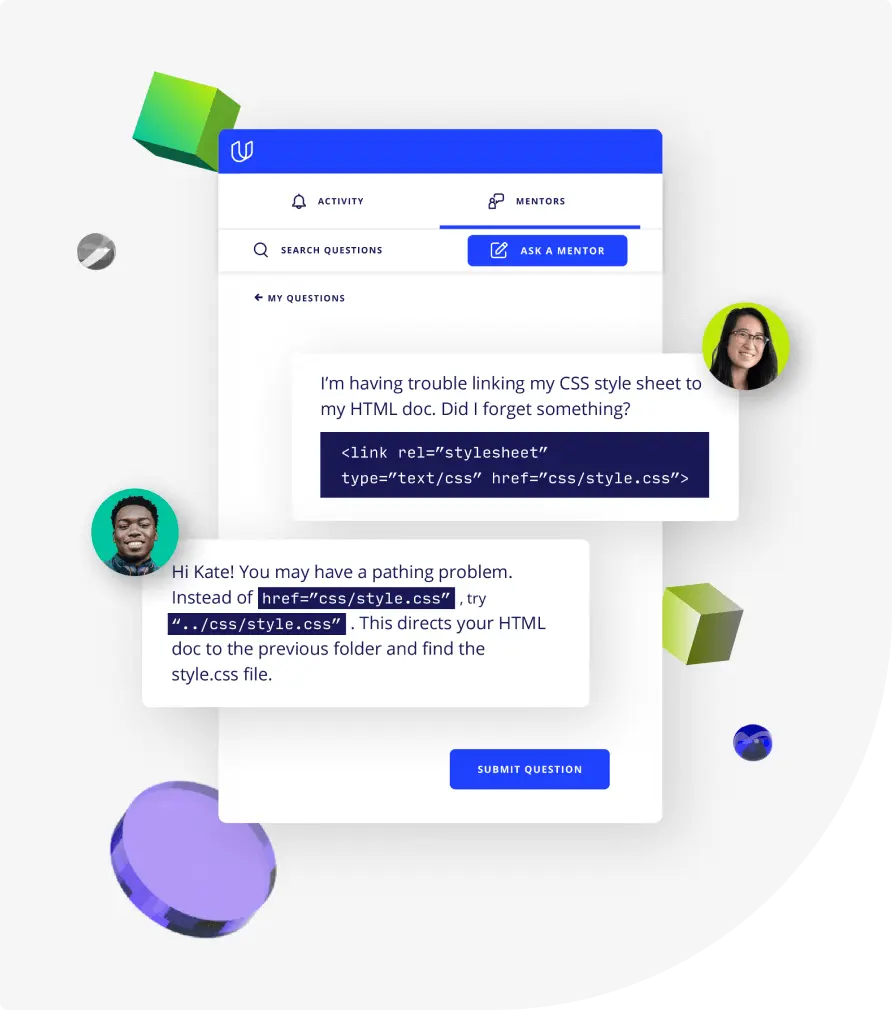
Top-tier services to ensure learner success
Reviewers provide timely and constructive feedback on your project submissions, highlighting areas of improvement and offering practical tips to enhance your work.
Get help from subject matter experts
Learn industry best practices
Gain valuable insights and improve your skills
4 weeks
, Intermediate
23 hours
Beginner
4 weeks
, Intermediate
4 weeks
, Intermediate
4 weeks
, Intermediate
8 hours
14 hours
, Beginner
20 hours
, Intermediate
4 hours
, Beginner
10 hours
4 weeks
, Intermediate
23 hours
Beginner
4 weeks
, Intermediate
4 weeks
, Intermediate
4 weeks
, Intermediate
8 hours
14 hours
, Beginner
20 hours
, Intermediate
4 hours
, Beginner
10 hours