Lesson 1
An Introduction to Your Nanodegree Program
Welcome! We're so glad you're here. Join us in learning a bit more about what to expect and ways to succeed.

Nanodegree Program
Learn to design data models, build data warehouses and data lakes, automate data pipelines, and work with massive datasets.
Learn to design data models, build data warehouses and data lakes, automate data pipelines, and work with massive datasets.
Intermediate
4 months
Real-world Projects
Completion Certificate
Last Updated June 21, 2024
Skills you'll learn:
Prerequisites:
Course 1 • 45 minutes
Welcome!
Lesson 1
Welcome! We're so glad you're here. Join us in learning a bit more about what to expect and ways to succeed.
Lesson 2
You are starting a challenging but rewarding journey! Take 5 minutes to read how to get help with projects and content.
Course 2 • 4 weeks
Learn to create relational and NoSQL data models to fit the diverse needs of data consumers. Use ETL to build databases in PostgreSQL and Apache Cassandra.
Lesson 1
In this lesson, students will learn the basic difference between relational and non-relational databases, and how each type of database fits the diverse needs of data consumers.
Lesson 2
In this lesson, students understand the purpose of data modeling, the strengths and weaknesses of relational databases, and create schemas and tables in Postgres
Lesson 3
Students will understand when to use non-relational databases based on the data business needs, their strengths and weaknesses, and how to creates tables in Apache Cassandra.
Lesson 4 • Project
Students will model event data to create a non-relational database and ETL pipeline for a music streaming app. They will define queries and tables for a database built using Apache Cassandra.
Course 3 • 4 weeks
In this course, you’ll learn to create cloud-based data warehouses. You’ll sharpen your data warehousing skills, deepen your understanding of data infrastructure, and be introduced to data engineering on the cloud using Amazon Web Services (AWS).
Lesson 1
Welcome to Cloud Data Warehouse with Amazon Web Services. In this lesson, you'll learn more about the course and set yourself up for success!
Lesson 2
In this lesson, you'll be introduced to the business case for data warehouses as well as architecture, extracting, transforming, and loading data, data modeling, and data warehouse technologies.
Lesson 3
In this lesson, you'll learn about ELT, the differences between ETL and ELT, and general cloud data warehouse technologies.
Lesson 4
In this lesson, you'll learn about AWS Services and how to set up Amazon S3, IAM, VPC, EC2, and RDS. You'll build a Redshift data warehouse cluster and learn how to interact with it.
Lesson 5
In this lesson, you'll learn to implement a data warehouse on AWS
Lesson 6 • Project
In this project, you'll build an ETL pipeline that extracts data from S3, stages data in Redshift, and transforms data into a set of dimensional tables for an analytics team.
Course 4 • 4 weeks
In this course, you will learn about the big data ecosystem and how to use Spark to work with massive datasets. You’ll also learn about how to store big data in a data lake and query it with Spark.
Lesson 1
In this course you'll learn how Spark evaluates code and uses distributed computing to process and transform data. You'll work in the big data ecosystem to build data lakes and data lake houses.
Lesson 2
In this lesson, you will learn about the problems that Apache Spark is designed to solve. You'll also learn about the greater Big Data ecosystem and how Spark fits into it.
Lesson 3
In this lesson, we'll dive into how to use Spark for wrangling, filtering, and transforming distributed data with PySpark and Spark SQL
Lesson 4
In this lesson, you will learn to use Spark and work with data lakes with Amazon Web Services using S3, AWS Glue, and AWS Glue Studio.
Lesson 5
In this lesson you'll work with Lakehouse zones. You will build and configure these zones in AWS.
Lesson 6 • Project
In this project, you'll work with sensor data that trains a machine learning model. You'll load S3 JSON data from a data lake into Athena tables using Spark and AWS Glue.

Professor at Brigham Young University Idaho
Sean currently teaches cybersecurity and DevOps courses at Brigham Young University Idaho. He has been a software engineer for over 16 years. Some of the most exciting projects he has worked on involved data pipelines for DNA processing and vehicle telematics.

General Manager, MBS
Matt has been working in software development and data science for over 20 years. Matt's career is centered on the intersection of technology, data, and human psychology. He is passionate about using data science to have a meaningful impact on our people and our planet.

Staff Engineer at SpotHero
In his career as an engineer, Ben Goldberg has worked in fields ranging from computer vision to natural language processing. At SpotHero, he founded and built out their data engineering team, using Airflow as one of the key technologies.

Developer Advocate at DataStax
Amanda is a developer advocate for DataStax after spending the last 6 years as a software engineer on 4 different distributed databases. Her passion is bridging the gap between customers and engineering. She has degrees from the University of Washington and Santa Clara University.

Senior Technical Content Developer at Udacity
Valerie is a Sr. Technical Content Developer at Udacity who has developed and taught a broad range of computing curricula for multiple colleges and universities. She is a former professor and software engineer for over 10 years specializing in web, mobile, voice assistant, and full-stack application development.
Average Rating: 4.6 Stars
1,132 Reviews
Navreen K.
April 12, 2023
It's a great learning for upskilling yourself.
Nicolas M.
February 14, 2023
Once you get going, it gets really interesting and the topics are covered really well. Some issues with AWS console that should be address to make easier life for users. As Cluster generation errors due to new version of AWS for capstone and airflow projects. The rest, really good
Prem Digdesh M.
December 22, 2022
The program is really great and the hand on project provides a great understanding of the concepts taught in the course lectures.
Felipe L.
December 2, 2022
Very good explanations and contents
Jaeseok P.
November 19, 2022
The meat of this course is in the projects. There is a lot of thought that went into the project design, I think it is the right mix of independence and guidance. The review process is spot-on.
Combine technology training for employees with industry experts, mentors, and projects, for critical thinking that pushes innovation. Our proven upskilling system goes after success—relentlessly.

Demonstrate proficiency with practical projects
Projects are based on real-world scenarios and challenges, allowing you to apply the skills you learn to practical situations, while giving you real hands-on experience.
Gain proven experience
Retain knowledge longer
Apply new skills immediately
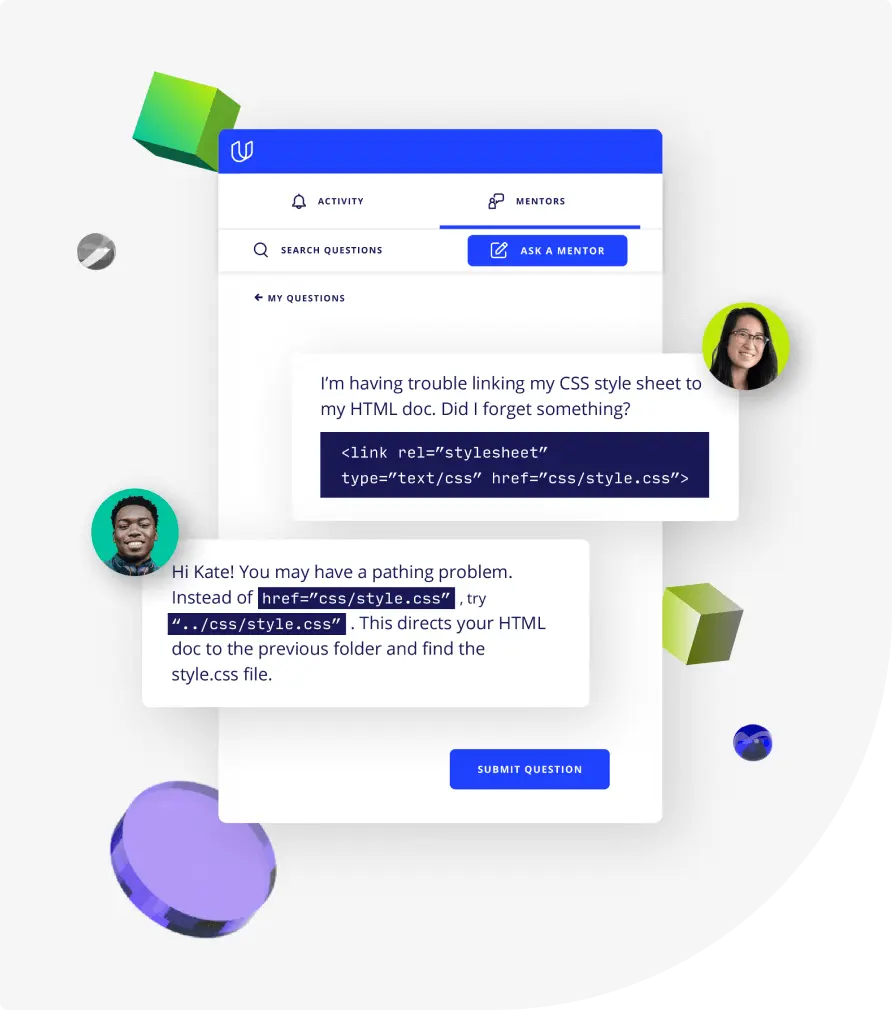
Top-tier services to ensure learner success
Reviewers provide timely and constructive feedback on your project submissions, highlighting areas of improvement and offering practical tips to enhance your work.
Get help from subject matter experts
Learn industry best practices
Gain valuable insights and improve your skills

Full Catalog Access
One subscription opens up this course and our entire catalog of projects and skills.
Average time to complete a Nanodegree program
(2)
4 months
, Advanced
(80)
4 months
, Advanced
(781)
4 months
, Advanced
(41)
5 months
, Intermediate
(416)
4 months
, Intermediate
1 month
, Advanced
(62)
3 months
, Intermediate
(398)
3 months
, Intermediate
(174)
2 months
, Advanced
(807)
2 months
, Beginner
4 weeks
, Intermediate
(127)
2 months
, Advanced
3 weeks
, Advanced
(34)
4 months
, Intermediate
4 weeks
, Intermediate
(124)
5 months
, Beginner
(2)
4 months
, Advanced
(80)
4 months
, Advanced
(781)
4 months
, Advanced
(41)
5 months
, Intermediate
(416)
4 months
, Intermediate
1 month
, Advanced
(62)
3 months
, Intermediate
(398)
3 months
, Intermediate
(174)
2 months
, Advanced
(807)
2 months
, Beginner
4 weeks
, Intermediate
(127)
2 months
, Advanced
3 weeks
, Advanced
(34)
4 months
, Intermediate
4 weeks
, Intermediate
(124)
5 months
, Beginner

Data Engineering with AWS
(2)
4 months
, Advanced
(80)
4 months
, Advanced
(781)
4 months
, Advanced
(41)
5 months
, Intermediate
(416)
4 months
, Intermediate
1 month
, Advanced
(62)
3 months
, Intermediate
(398)
3 months
, Intermediate
(174)
2 months
, Advanced
(807)
2 months
, Beginner
4 weeks
, Intermediate
(127)
2 months
, Advanced
3 weeks
, Advanced
(34)
4 months
, Intermediate
4 weeks
, Intermediate
(124)
5 months
, Beginner
(2)
4 months
, Advanced
(80)
4 months
, Advanced
(781)
4 months
, Advanced
(41)
5 months
, Intermediate
(416)
4 months
, Intermediate
1 month
, Advanced
(62)
3 months
, Intermediate
(398)
3 months
, Intermediate
(174)
2 months
, Advanced
(807)
2 months
, Beginner
4 weeks
, Intermediate
(127)
2 months
, Advanced
3 weeks
, Advanced
(34)
4 months
, Intermediate
4 weeks
, Intermediate
(124)
5 months
, Beginner
Our Data Engineering Nanodegree program is a comprehensive data engineering course designed to teach you how to design data models, build data warehouses and data lakes, automate data pipelines, and work with massive datasets. Skills covered include Database fundamentals, CassandraDB, PostgreSQL, and database normalization. This program is ideal for those with a basic understanding of Python, SQL, and command-line interfaces. You'll learn from industry experts like Sean Murdock, Matt Swaffer, Ben Goldberg, Amanda Moran, and Valerie Scarlata, gaining hands-on experience with real-world projects. At Udacity, we offer an empowering learning environment where you gain practical skills through our data engineering training, reinforced with top-tier support and expert feedback. This course will equip you with the knowledge and tools to excel in the field of data engineering.