Users of relational databases want all the data they need at their fingertips, while the database designers want to responsibly “decompose” the data into the smallest possible and most efficient tables. There’s always a tension between ease and efficiency at scale.
SQL Join satisfyingly bridges this tension, giving you the power to derive tables that contain exactly the data you need.
SQL Join generates a new (temporary or permanent) table from one or more tables by combining columns based on the way the Join is invoked. There’s also a “self-join” variant to groom an unruly table into something more manageable.
Types of SQL Join
ANSI-standard SQL specifies the following types of JOIN:
- Inner Join — returns rows that have a matching value in both tables
- Left Join — returns all rows from the left table and matching rows from the right table
- Right Join — returns all rows from the right table and matching rows from the left table
- Full (Outer) Join — returns all rows when there’s a match on either the left or right table
- Cross Join — returns all rows from the left table combined with the rows from the right table
Further cleaning up of the resulting table is (optionally) done by adding clauses to the SQL Join, so that a minimum of data needs to be transmitted and stored. A practical discussion will make these set operations clear. Let’s SQL Join some tables which describe students taking online courses.
The Tables We’ll Join
Our first table describes the pupils enjoying the benefits of higher learning. This very minimal table consists of their name and a numeric course ID. (A real-world implementation would have student IDs, email and postal addresses, tuition balance, etc.)
STUDENTS:

The NULL value shows a student has been registered in this scheme but not yet chosen coursework.
Another table contains the course ID and a human-readable course name. (A real-world implementation might have a course blurb and detailed description, cost, etc.)
In a perfect world both Students.Course and Nano_Degrees.ID would have the same name; perhaps “Course” would have been a better choice for both during the design process. In practice, however, software systems are the result of accretion of decisions over time; you’ll face column names that seemed to make sense at the time and may not have aged well. I’ve deliberately chosen different names to demonstrate how to map these common columns in the Joins.
What’s key to Inner Join is that there’s a direct mapping between Students.Course and Nano_Degrees.ID. It’s this commonality that lets us Join these two tables into one.
NANO_DEGREES:

The NULL values in the last two rows show a course (ID 6) that has been approved but not yet named and another (ID NULL) which is a placeholder for a proposed course that hasn’t been approved and given an ID. (These sorts of things may not crop up in well-designed and -managed tables but in the real world NULL can appear everywhere and your code must anticipate them.)
Now that we have the database schema in mind and sample data upon which to operate, let’s actually SQL Join them together.
Run these SQL code samples yourself at http://sqlfiddle.com/. The SQL to create and populate these sample tables is included at the end of this article.
Inner Join
The Inner Join is the combining operation usually visualized when being first exposed to SQL Join; it creates a table with the values appearing together in the way that’s typically imagined when designing database relationships. For example, a table of students and their coursework was probably sketched on a napkin in a café looking like this:

Recreating the table sketched on that napkin from the decomposed versions implemented by the database developers — such that strings like “Flying Car and Autonomous Flight Engineer” aren’t expensively repeated — is done with an Inner Join.
SELECT
STUDENTS.PERSON, NANO_DEGREES.NAME
FROM
STUDENTS
INNER JOIN
NANO_DEGREES ON STUDENTS.COURSE=NANO_DEGREES.ID ;
The result omits students not taking coursework, those with NULL entries.

Take great care when joining tables on columns that can contain NULL values; NULL never matches any other value – not even NULL itself. Use a combination predicate that first checks that the joins columns are NOT NULL before applying the remaining predicate condition(s). Not heeding this warning will result in eliminated rows that have a NULL value in a joining column.
Outer Join
Whereas INNER JOIN zips together two tables that share a common index column, The Outer Joins returns rows that satisfy the operation specified; Left or Right.
In the following examples I’m using the wildcard character * instead of specifying exactly what should be returned, e.g. SELECT STUDENTS.PERSON, NANO_DEGREES.NAME, to show better how the Join works and how much more data must be transmitted and stored; decreasing response time and conserving data storage are hallmarks of scalable, efficient code.
Left Join
The Left Join returns all the rows from the left-side table with matching values from the right-hand side table. Where there’s no match a NULL appears.
SELECT
*
FROM
STUDENTS
LEFT JOIN
NANO_DEGREES ON STUDENTS.COURSE=NANO_DEGREES.ID ;
The results of our Left Join contains rows with NULL values.
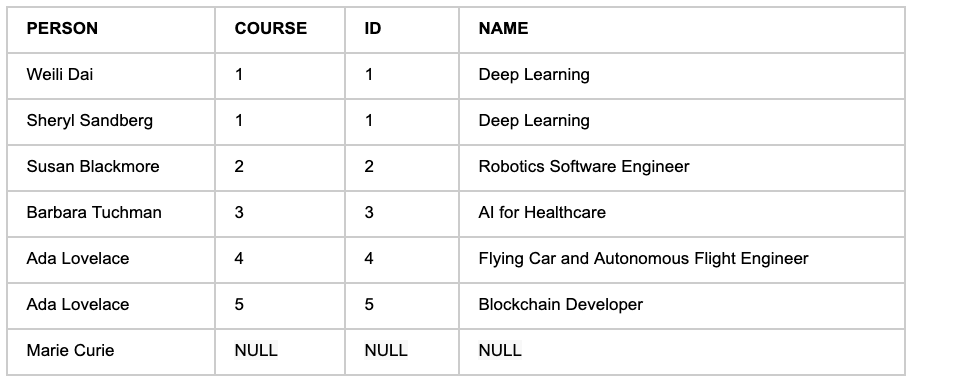
Unlike the Inner Join, above, here NULLs are shown because there’s a mapping mismatch between the tables. Note that both the COURSE and ID columns are both returned with the ‘*’ wildcard operator.
Right Join
The Right Join returns all the rows from the right-side table with matching values from the left-hand side table. Where there’s no match a NULL appears.
SELECT
*
FROM
STUDENTS
RIGHT JOIN
NANO_DEGREES ON STUDENTS.COURSE=NANO_DEGREES.ID ;
The results of our Right Join also contains rows with NULL values.
The row order in the resulting table differs from the previous JOIN example, above, because the operation is focussing on the right-hand table. Never assume a particular row order from whichever SQL implementation you’re using; that way lies madness. Always specify ORDER BY {ASC|DESC} for your SQL if your code which consumes the results is dependent upon order.
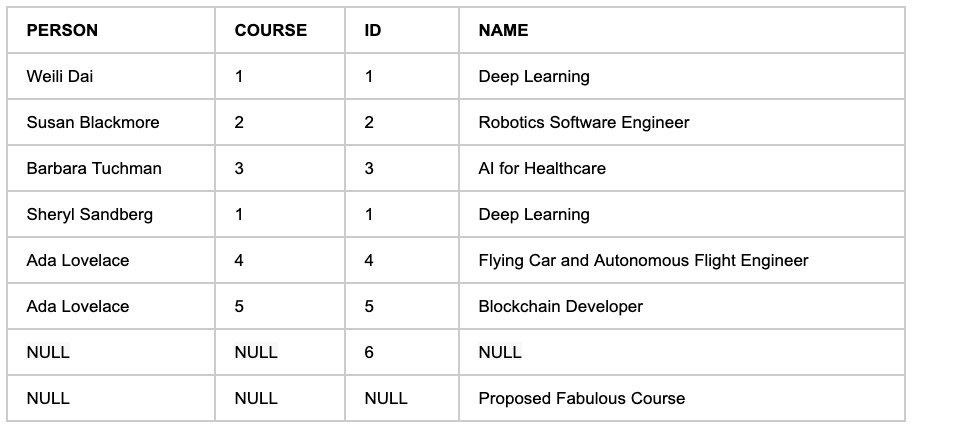
Unlike the Inner Join, above, here NULLs are shown because there’s a mapping mismatch between the tables. This is an expected behavior of the Outer Joins.
Cross Join
A Cross Join returns all rows from the combination of the left and right tables.
SELECT
*
FROM
STUDENTS
CROSS JOIN
NANO_DEGREES ;
The output from a Cross Join is long, so only the beginning fragment is shown here.
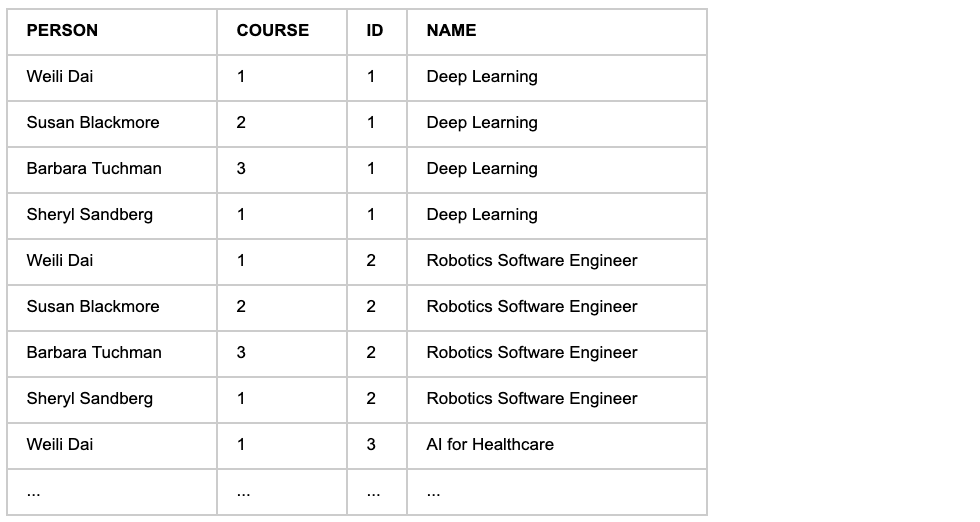
Conclusion
Experienced database programmers are familiar with “nesting” SQL queries, using the output from one as the input to the next, in a chain.
Using a single Join instead of multiple nested queries speeds up application execution by saving on…
- the amount of data transferred from the database engine to your application code;
- the amount of memory used and computation cycles needed to individually retrieve each of; the nested queries and pipe them to the next query.
Even more importantly, a well-crafted Join is easier to understand today and also next year, resulting in lower software maintenance costs, faster bug-fixing cycles, and happier software engineers. To learn more about SQL, enroll in our SQL Nanodegree program, described in detail here.
SQL Join Sample Table Code
The following SQL will build and populate the sample tables used in this article:
CREATE TABLE STUDENTS (
PERSON VARCHAR(33) NOT NULL,
COURSE INT ) ;
CREATE TABLE NANO_DEGREES (
ID INT,
NAME VARCHAR(99) ) ;
INSERT INTO
STUDENTS
VALUES
( 'Weili Dai', 1 ),
( 'Susan Blackmore', 2 ),
( 'Barbara Tuchman', 3 ),
( 'Sheryl Sandberg', 1 ),
( 'Ada Lovelace', 4 ),
( 'Ada Lovelace', 5 ),
( 'Marie Curie', NULL ) ;
INSERT INTO
NANO_DEGREES
VALUES
( 1, 'Deep Learning' ),
( 2, 'Robotics Software Engineer' ),
( 3, 'AI for Healthcare' ),
( 4, 'Flying Car and Autonomous Flight Engineer' ),
( 5, 'Blockchain Developer' ),
( 6, NULL ),
( NULL, 'Proposed Fabulous Course' ) ;



