
Lesson 1
Clustering
Clustering is one of the most common methods of unsupervised learning. Here, we'll discuss the K-means clustering algorithm.

Course
In this course, you'll learn how to apply unsupervised learning to solve real-world problems.
In this course, you'll learn how to apply unsupervised learning to solve real-world problems.
Intermediate
4 weeks
Real-world Projects
Completion Certificate
Last Updated March 18, 2024
Lesson 1
Clustering is one of the most common methods of unsupervised learning. Here, we'll discuss the K-means clustering algorithm.
Lesson 2
We continue to look at clustering methods. Here, we'll discuss hierarchical clustering and density-based clustering (DBSCAN).
Lesson 3
In this lesson, we discuss Gaussian mixture model clustering. We then talk about the cluster analysis process and how to validate clustering results.
Lesson 4
Often we need to reduce a large number of features in our data to a smaller, more relevant set. Principal Component Analysis, or PCA, is a method of feature extraction and dimensionality reduction.
Lesson 5
In this lesson, we will look at two other methods for feature extraction and dimensionality reduction: Random Projection and Independent Component Analysis (ICA).
Lesson 6 • Project
In this project, you'll apply your unsupervised learning skills to two demographics datasets, to identify segments and clusters in the population, and see how customers of a company map to them.

Staff Data Scientist
Josh has been sharing his passion for data for over a decade. He's used data science for work ranging from cancer research to process automation. He recently has found a passion for solving data science problems within marketplace companies.

Instructor
Jay is a software engineer, the founder of Qaym (an Arabic-language review site), and the Investment Principal at STV, a $500 million venture capital fund focused on high-technology startups.
Combine technology training for employees with industry experts, mentors, and projects, for critical thinking that pushes innovation. Our proven upskilling system goes after success—relentlessly.

Demonstrate proficiency with practical projects
Projects are based on real-world scenarios and challenges, allowing you to apply the skills you learn to practical situations, while giving you real hands-on experience.
Gain proven experience
Retain knowledge longer
Apply new skills immediately
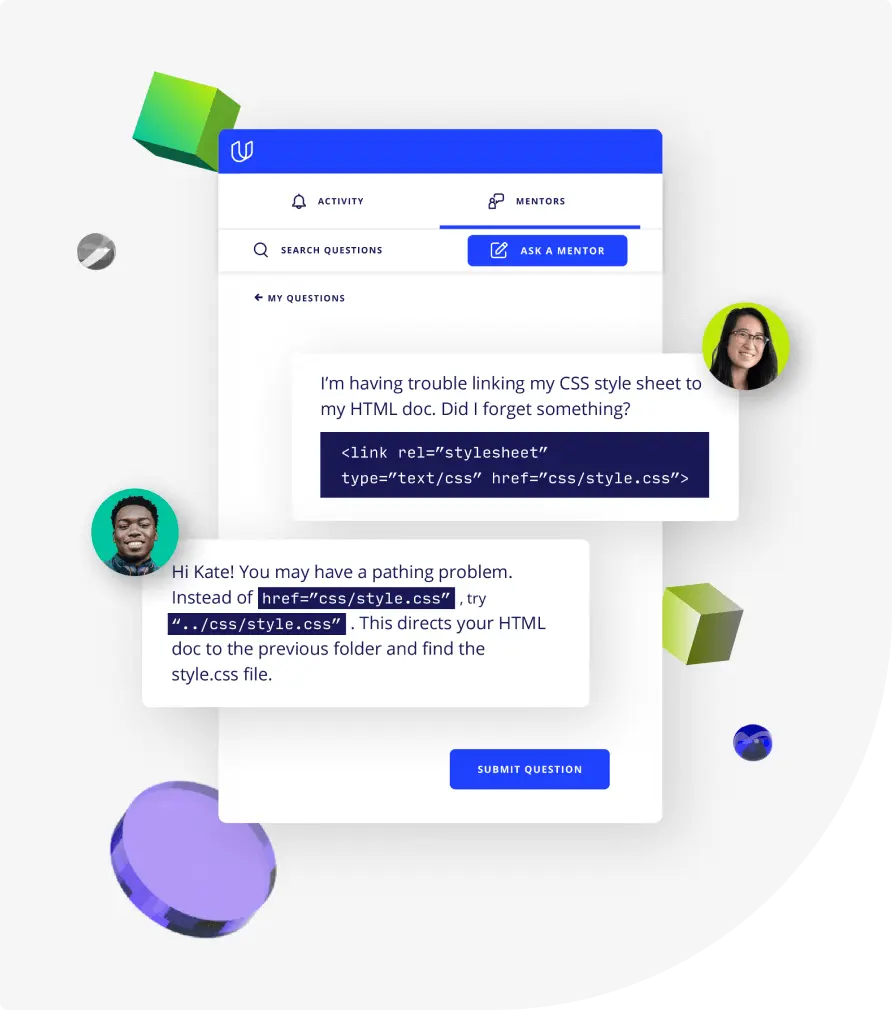
Top-tier services to ensure learner success
Reviewers provide timely and constructive feedback on your project submissions, highlighting areas of improvement and offering practical tips to enhance your work.
Get help from subject matter experts
Learn industry best practices
Gain valuable insights and improve your skills

Unlimited access to our top-rated courses
Real-world projects
Personalized project reviews
Program certificates
Proven career outcomes
Full Catalog Access
One subscription opens up this course and our entire catalog of projects and skills.
Average time to complete a Nanodegree program

Unsupervised Learning